Artículo
Bases de datos en memoria y almacenamiento en caché: velocidad a escala
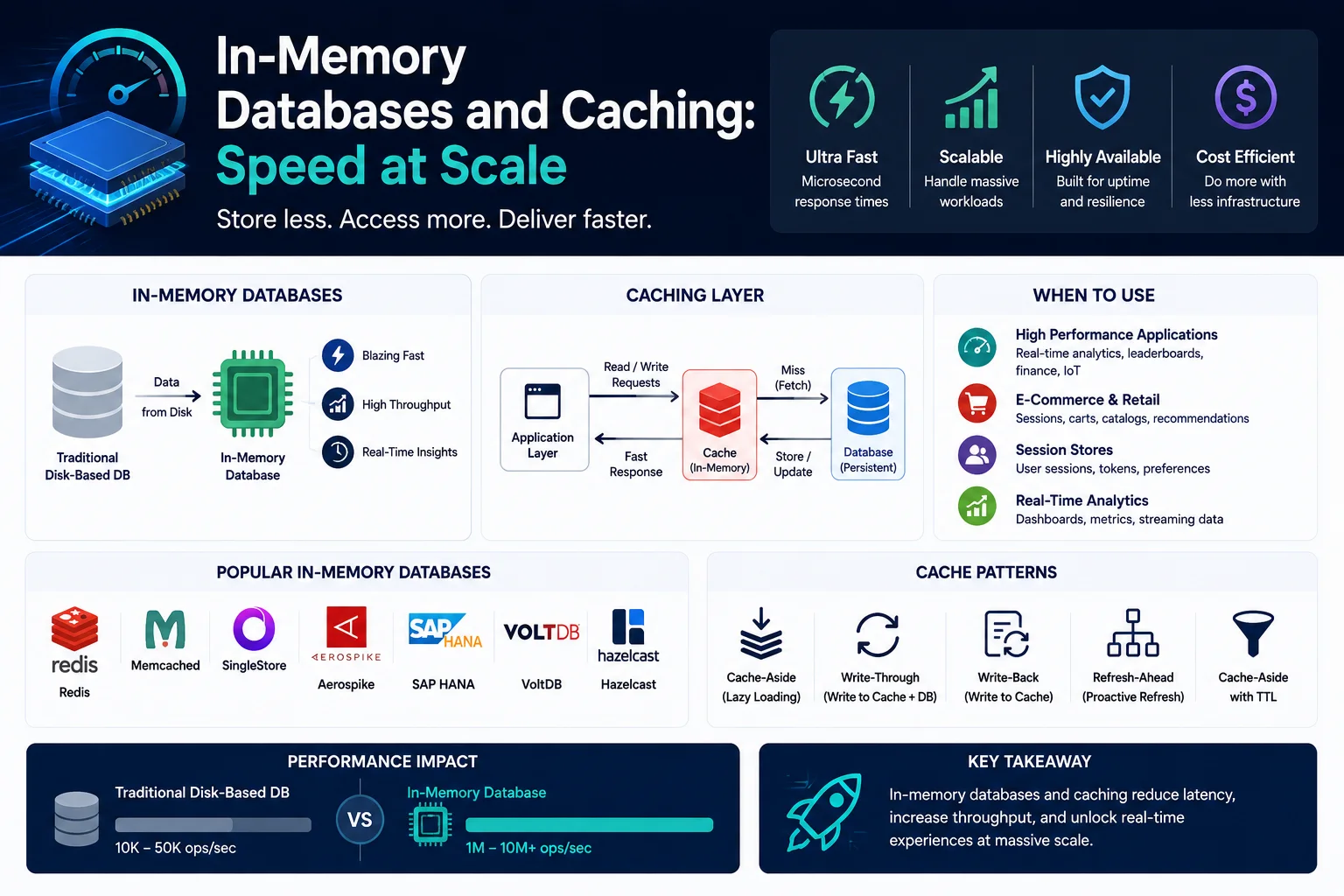
Las bases de datos en memoria almacenan datos principalmente en la RAM y no en el disco. Esto elimina la latencia de E/S del disco, proporcionando tiempos de respuesta de microsegundos, órdenes de magnitud más rápidos que las bases de datos tradicionales basadas en disco.
3 min de lecturaIdioma: ES EspañolGratis0 aplausos0 comentarios
TecnologíaArtículos de ingenieríaCachingDatabasesTechnologyEngineering ArticlesMemory
Opciones de lectura
Introducción
Las bases de datos en memoria almacenan datos principalmente en la RAM y no en el disco. Esto elimina la latencia de E/S del disco, proporcionando tiempos de respuesta de microsegundos, órdenes de magnitud más rápidos que las bases de datos tradicionales basadas en disco.
Las bases de datos en memoria no reemplazan a las bases de datos tradicionales: son complementarias. Se destacan en casos de uso que requieren latencia ultrabaja, alto rendimiento y procesamiento de datos en tiempo real: almacenamiento en caché, gestión de sesiones, análisis en tiempo real, tablas de clasificación, limitación de velocidad e intermediación de mensajes.
Bases de datos en memoria frente a bases de datos basadas en disco
| Aspecto | Base de datos en memoria | Base de datos basada en disco |
|---|---|---|
| Almacenamiento primario | RAM | SSD/HDD |
| Leer latencia | < 1 ms (típico 0,1 ms) | 1-10 ms (SSD), 5-20 ms (HDD) |
| Rendimiento de escritura | 100K-1M+ operaciones/seg | 1K-100K operaciones/seg |
| Persistencia de datos | Opcional (instantáneas, AOF) | Siempre persistente |
| Capacidad | RAM limitada (GB-TB) | Disco limitado (TB-PB) |
| Coste por GB | ~$10-50/GB | ~$0.10-1/GB |
| Complejidad de la consulta | Valor-clave, estructuras simples | Uniones complejas, agregaciones |
| Durabilidad | Configurable (compensación de fsync) | Garantías ACID totales |
Redis: la tienda en memoria más popular
Estructuras de datos
# Strings — most basic
SET user:100:name "Alice"
GET user:100:name # "Alice"
INCR page_counter # 1
INCRBY page_counter 5 # 6
# Lists — ordered, push/pop from ends
LPUSH notifications:101 "New message"
RPOP notifications:101 # "New message"
LLEN notifications:101 # Length
# Sets — unordered, unique members
SADD user:100:tags "redis" "python" "database"
SMEMBERS user:100:tags # All members
SISMEMBER user:100:tags "python" # 1 (true)
SINTER user:100:tags user:200:tags # Intersection
# Sorted Sets — scored, ordered
ZADD leaderboard 1000 "player1"
ZADD leaderboard 2500 "player2" 900 "player3"
ZREVRANGE leaderboard 0 2 WITHSCORES # Top 3
# 1) "player2" (2500)
# 2) "player3" (900)
# 3) "player1" (1000)
# Hashes — structured objects
HSET user:100 name "Alice" age 30 email "alice@example.com"
HGETALL user:100
HINCRBY user:100 login_count 1
# Streams — append-only log (like Kafka)
XADD events * type "login" user_id "100"
XRANGE events - + COUNT 10
# Geospatial — location-based
GEOADD locations 13.361389 38.115556 "Palermo"
GEORADIUS locations 15 37 100 km # Cities within 100km
Opciones de persistencia
| Modo | Cómo funciona | Durabilidad | Impacto en el rendimiento |
|---|---|---|---|
| RDB (instantánea) | Volcado completo periódico al disco | Último volcado perdido | Bajo (bifurcación + escritura) |
| AOF (solo anexar) | Cada escritura registrada | Configurable: siempre/seg/no | Medio |
| RDB + AOF | Ambos combinados | Alto | Medio |
| Sin persistencia | Sólo RAM, sin E/S de disco | Ninguno al reiniciar | Mejor rendimiento |
# redis.conf — persistence configuration
save 900 1 # RDB: save if 1 key changed in 900 seconds
save 300 10 # save if 10 keys changed in 300 seconds
save 60 10000 # save if 10000 keys changed in 60 seconds
appendonly yes # Enable AOF
appendfsync everysec # fsync every second (best trade-off)
Producción Redis Arquitectura
Réplica maestra:
Client ──► Master (read/write)
│
┌────┴────┐
│ │
Replica1 Replica2 (read-only, failover targets)
Redis Sentinel: alta disponibilidad:
┌──────────┐
│ Sentinel │ (monitors master, performs automatic failover)
└──────────┘
│
Client ──► Master ──► Replica1 ──► Replica2
│
(if master fails, Sentinel promotes a replica)
Clúster de Redis: fragmentación:
Client ──► Any node (auto-redirect to correct shard)
Shard 1 (Master A + Replica A')
Shard 2 (Master B + Replica B')
Shard 3 (Master C + Replica C')
Hash slots: 0-16383 distributed across shards
No central proxy — clients connect directly
Patrones de almacenamiento en caché
Caché aparte (carga diferida):
def get_user(user_id: str) -> dict:
# Try cache first
cached = redis.get(f"user:{user_id}")
if cached:
return json.loads(cached)
# Cache miss — load from database
user = db.query("SELECT * FROM users WHERE id = %s", user_id)
# Store in cache with TTL
redis.setex(f"user:{user_id}", 3600, json.dumps(user))
return user
Escritura directa:
def update_user(user_id: str, data: dict):
# Update database
db.execute("UPDATE users SET ... WHERE id = %s", data, user_id)
# Update cache immediately
redis.setex(f"user:{user_id}", 3600, json.dumps(data))
Escritura retrasada (asincrónica):
def write_behind(user_id: str, data: dict):
# First to cache (instant)
redis.setex(f"user:{user_id}", 3600, json.dumps(data))
# Queue for async database write
redis.lpush("write_queue", json.dumps({
'user_id': user_id,
'data': data,
'timestamp': time.time()
}))
# Background worker processes the queue
def write_worker():
while True:
task = json.loads(redis.brpop("write_queue")[1])
db.execute("UPDATE users SET ... WHERE id = %s",
task['data'], task['user_id'])
Estrategias de almacenamiento en caché
Estrategias de invalidación de caché
| Estrategia | Mecanismo | Mejor para |
|---|---|---|
| Basado en TTL | Establecer tiempo de vida y caducidad automática | Datos obsoletos aceptables |
| Escritura simultánea | Actualizar caché en cada escritura | Lectura intensa, escritura ligera |
| Escritura retrasada | Escritura asíncrona en base de datos | Escritura intensa, consistencia eventual OK |
| Invalidación de caché | Eliminación/actualización explícita | Se necesita una fuerte coherencia |
| Basado en versiones | La clave de caché incluye la versión | Cambios de esquema |
Políticas de desalojo
| Política | Descripción | Caso de uso |
|---|---|---|
| LRU (Usado menos recientemente) | Desalojar la clave más antigua a la que se accedió | Propósito general |
| LFU (Uso menos frecuente) | Desalojar la clave menos accedida | Patrones de acceso estables |
| TTL | Claves con caducidad automática | Datos de sesión, caché temporal |
| Aleatorio | Desalojo aleatorio | Sencillo, predecible |
| Sin desalojo | Error de devolución en memoria llena | Los datos críticos deben permanecer |
# Redis eviction policy
maxmemory 4gb
maxmemory-policy allkeys-lru # or: volatile-lru, allkeys-lfu, volatile-ttl
Otras bases de datos en memoria
Memcached: simple, rápido y multiproceso
# Simple key-value (no persistence, no replication)
memcached -m 4096 -p 11211 -t 4
# Usage (similar to Redis but simpler)
set user:100 0 3600 15 # key, flags, ttl, byte_count
"Hello, World!"
get user:100
Redis frente a Memcached:
| Característica | Redis | Memcached |
|---|---|---|
| Estructuras de datos | Cadenas, listas, conjuntos, hashes, secuencias, etc. | Solo cuerdas |
| Persistencia | RDB + AOF | Ninguno |
| Replicación | Réplica maestra + Clúster | Ninguno |
| Transacciones | MULTI/EXEC, Lua | Ninguno |
| Eficiencia de la memoria | Bueno (tiene opciones de compresión) | Mejor (menores gastos generales) |
| Enhebrado | Un solo subproceso (bucle de eventos) | multiproceso |
| Caso de uso | Caché de propósito general + estructuras de datos | Sólo caché simple |
Dragonfly: alternativa moderna a Redis
# Dragonfly is multi-threaded (faster on multi-core CPUs)
dragonfly --bind 0.0.0.0 --port 6379
# Same Redis protocol, same clients
redis-cli SET key value
redis-cli GET key
Hazelcast, Apache Ignite: cuadrículas de datos distribuidas en memoria
// Hazelcast — distributed cache with processing
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.map.IMap;
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IMap<String, User> cache = hz.getMap("users");
cache.put("user:100", user);
User cached = cache.get("user:100");
// Distributed computing
cache.executeOnKey("user:100", entry -> {
User user = entry.getValue();
user.incrementLoginCount();
entry.setValue(user);
return null;
});
Casos de uso comunes
1. Tiendas de sesiones
def create_session(user_id: str) -> str:
session_id = str(uuid.uuid4())
redis.setex(
f"session:{session_id}",
86400 * 7, # 7 days
json.dumps({
'user_id': user_id,
'created_at': time.time(),
'ip': request.remote_addr,
'user_agent': request.user_agent,
})
)
return session_id
def validate_session(session_id: str) -> dict | None:
data = redis.get(f"session:{session_id}")
if data:
return json.loads(data)
return None
2. Limitación de tasa
import time
def check_rate_limit(user_id: str, max_requests: int = 100,
window_seconds: int = 60) -> bool:
key = f"ratelimit:{user_id}:{int(time.time()) // window_seconds}"
count = redis.incr(key)
if count == 1:
redis.expire(key, window_seconds)
return count <= max_requests
# Token bucket algorithm (more precise)
def token_bucket(user_id: str, capacity: int = 100,
refill_rate: float = 1.0) -> bool:
key = f"token_bucket:{user_id}"
now = time.time()
lua = """
local key = KEYS[1]
local now = tonumber(ARGV[1])
local capacity = tonumber(ARGV[2])
local refill_rate = tonumber(ARGV[3])
local bucket = redis.call('HMGET', key, 'tokens', 'last_refill')
local tokens = tonumber(bucket[1]) or capacity
local last_refill = tonumber(bucket[2]) or now
local elapsed = now - last_refill
tokens = math.min(capacity, tokens + elapsed * refill_rate)
if tokens >= 1 then
tokens = tokens - 1
redis.call('HMSET', key, 'tokens', tokens, 'last_refill', now)
return 1
else
return 0
end
"""
return bool(redis.eval(lua, 1, key, now, capacity, refill_rate))
3. Tablas de clasificación en tiempo real
def add_score(game_id: str, player: str, score: int):
redis.zadd(f"leaderboard:{game_id}", {player: score})
def get_top_players(game_id: str, n: int = 10) -> list[dict]:
results = redis.zrevrange(
f"leaderboard:{game_id}", 0, n - 1,
withscores=True
)
return [
{"player": player.decode(), "score": int(score)}
for player, score in results
]
def get_player_rank(game_id: str, player: str) -> int:
rank = redis.zrevrank(f"leaderboard:{game_id}", player)
return rank + 1 if rank is not None else None
4. Cola de mensajes/Pub-Sub
# PUBLISH/SUBSCRIBE
# Publisher
redis.publish("notifications:global",
json.dumps({"type": "alert", "message": "System update at 2AM"}))
# Subscriber (separate process)
pubsub = redis.pubsub()
pubsub.subscribe("notifications:global")
for message in pubsub.listen():
if message['type'] == 'message':
process_notification(json.loads(message['data']))
# List-based queue (reliable)
redis.lpush("task_queue", json.dumps(task))
task = redis.brpop("task_queue") # Blocking pop
Optimización del rendimiento
Impacto de la serialización
| Formato | Serialización | Deserialización | Tamaño (1000 artículos) |
|---|---|---|---|
| Pepinillo (Python) | 1x | 1x | 100KB |
| JSON | 0,8x | 0,7x | 180KB |
| Paquete de mensajes | 0,6x | 0,5x | 130KB |
| Protobuf | 0,9x | 0,4x | 75KB |
| Binario personalizado | 0,3x | 0,2x | 55 KB |
Tubería (Reducir viajes de ida y vuelta)
# Without pipeline: N round-trips
for user_id in user_ids:
redis.get(f"user:{user_id}") # N network calls
# With pipeline: 1 round-trip
pipe = redis.pipeline()
for user_id in user_ids:
pipe.get(f"user:{user_id}")
results = pipe.execute() # Single network call
Agrupación de conexiones
import redis
class RedisPool:
_instance = None
_pool = None
@classmethod
def get_connection(cls) -> redis.Redis:
if cls._pool is None:
cls._pool = redis.ConnectionPool(
host='redis-cluster.example.com',
port=6379,
max_connections=100,
socket_timeout=2,
retry_on_timeout=True,
health_check_interval=30,
)
return redis.Redis(connection_pool=cls._pool)
Monitoreo
# Redis INFO
redis-cli INFO
# Key metrics to monitor:
connected_clients: 42
used_memory_human: 3.2G
used_memory_peak_human: 4.1G
total_commands_processed: 15238912
keyspace_hits: 984532
keyspace_misses: 5214
expired_keys: 11245
evicted_keys: 0
instantaneous_ops_per_sec: 4532
| Métrica | Advertencia | Crítico | acción |
|---|---|---|---|
| Uso de memoria | > 80% de la memoria máxima | > 95% | Ampliar y optimizar TTL |
| Tasa de aciertos | <85% | < 70% | Revisar la estrategia de almacenamiento en caché |
| Retraso de replicación | > 1 segundo | > 10 segundos | Comprobar red, réplica |
| llaves desalojadas | > 0 | > 100/hora | Aumentar memoria o TTL |
Conclusión
Las bases de datos en memoria son una infraestructura esencial para aplicaciones modernas y de alto rendimiento:
- Uso para almacenamiento en caché: reduzca la carga de la base de datos y mejore los tiempos de respuesta.
- Úselo para datos en tiempo real: tablas de clasificación, limitación de velocidad, gestión de sesiones.
- Úselo como intermediario de mensajes: Pub/sub, colas de tareas, flujos de eventos.
- Redis es la opción predeterminada: estructuras de datos enriquecidas, opciones de persistencia, agrupación en clústeres.
- Nunca utilizar como base de datos principal: riesgo de pérdida de datos, limitaciones de memoria, capacidad de consulta limitada.
Marco de decisión
Need sub-millisecond latency?
├─ Yes
│ Q: Complexity of operations?
│ ├─ Simple key-value: Memcached
│ ├─ Data structures, persistence: Redis
│ └─ Distributed computing: Hazelcast/Ignite
└─ No
Q: Data fits in memory?
├─ Yes: Consider in-memory for performance
└─ No: Disk-based (PostgreSQL, etc.)
Las bases de datos en memoria no sirven para reemplazar las bases de datos, sino para hacer que todo sea más rápido.
Comentarios
0 comentariosTodavía no hay comentarios aprobados. Las respuestas nuevas pueden esperar moderación.