Artículo
Bases de datos de gráficos: modelado de datos conectados
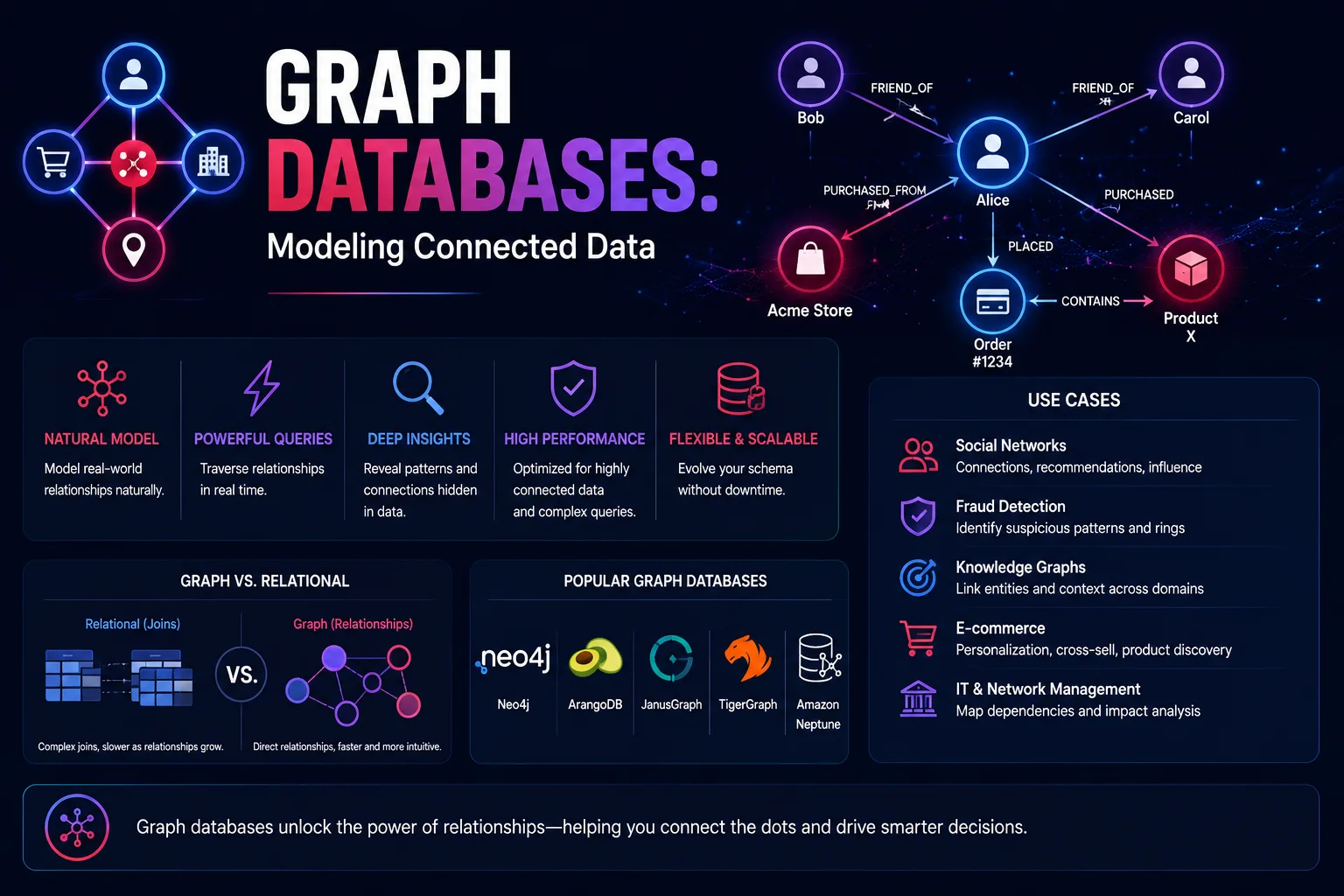
Las bases de datos de gráficos están diseñadas específicamente para almacenar y consultar datos altamente conectados. Mientras que las bases de datos relacionales destacan en datos tabulares con relaciones conocidas, las bases de datos gráficas destacan cuando las relaciones son tan importantes como los datos mismos: redes sociales, motores de recomendación, detección de fraude, gráficos de conocimiento y cadenas de suministro.
4 min de lecturaIdioma: ES EspañolGratis0 aplausos0 comentarios
TecnologíaArtículos de ingenieríaDatabasesTechnologyEngineering ArticlesGraphModeling
Opciones de lectura
Introducción
Las bases de datos de gráficos están diseñadas específicamente para almacenar y consultar datos altamente conectados. Mientras que las bases de datos relacionales destacan en datos tabulares con relaciones conocidas, las bases de datos gráficas destacan cuando las relaciones son tan importantes como los datos mismos: redes sociales, motores de recomendación, detección de fraude, gráficos de conocimiento y cadenas de suministro.
La idea fundamental: en muchos dominios, las conexiones entre entidades SON los datos, y las bases de datos gráficas convierten esas conexiones en un ciudadano de primera clase.
Conceptos de bases de datos de gráficos
Modelo de gráfico de propiedades
┌──────────────────┐
│ Person │
│ name: "Alice" │
│ age: 30 │
└────────┬─────────┘
│
┌────────▼─────────┐
│ KNOWS │
│ since: 2020 │
│ type: "friend" │
└────────┬─────────┘
│
┌────────▼─────────┐
│ Person │
│ name: "Bob" │
│ age: 32 │
└──────────────────┘
Tres componentes principales:
| Componente | Descripción | Ejemplo |
|---|---|---|
| Nodo (Vértice) | Una entidad en el gráfico. | Persona, Empresa, Producto |
| Borde (Relación) | Una conexión entre dos nodos. | SABE, TRABAJA, COMPRADO |
| Propiedad | Atributos en nodos o aristas | nombre: "Alicia", desde: 2020 |
Relacional versus gráfico
Consultar relaciones en SQL:
-- Find friends of friends who work at Google
SELECT DISTINCT p3.name
FROM persons p1
JOIN friendships f1 ON p1.id = f1.person_id
JOIN persons p2 ON f1.friend_id = p2.id
JOIN friendships f2 ON p2.id = f2.person_id
JOIN persons p3 ON f2.friend_id = p3.id
JOIN employment e ON p3.id = e.person_id
JOIN companies c ON e.company_id = c.id
WHERE p1.name = 'Alice'
AND c.name = 'Google';
Misma consulta en Cypher (Neo4j):
MATCH (alice:Person {name: "Alice"})
-[:KNOWS*2]->
(friend_of_friend:Person)
MATCH (friend_of_friend)-[:WORKS_AT]->(google:Company {name: "Google"})
RETURN DISTINCT friend_of_friend.name
Diferencia clave: SQL hace malabarismos con múltiples JOIN. Los recorridos de gráficos coinciden con los patrones de forma natural.
Lenguajes de consulta de gráficos
Cypher (Neo4j): coincidencia de patrones declarativos
// Create nodes and relationships
CREATE (alice:Person {name: "Alice", age: 30})
CREATE (bob:Person {name: "Bob", age: 32})
CREATE (alice)-[:KNOWS {since: 2020}]->(bob)
// Find friends of friends who bought products in the last month
MATCH (user:Person {id: $userId})
-[:KNOWS]->
(friend:Person)
-[:PURCHASED]->
(product:Product)
WHERE product.purchased_at > datetime() - duration('P1M')
RETURN product.name, count(*) as purchase_count
ORDER BY purchase_count DESC
LIMIT 10
// Shortest path between two people
MATCH p = shortestPath(
(alice:Person {name: "Alice"})-[:KNOWS*]-(bob:Person {name: "Bob"})
)
RETURN length(p) as degrees_of_separation,
[node IN nodes(p) | node.name] as path
Gremlin (Apache TinkerPop): recorrido de gráfico imperativo
// Same query in Gremlin
g.V().has('Person', 'name', 'Alice')
.repeat(out('KNOWS')).times(2)
.out('WORKS_AT')
.has('Company', 'name', 'Google')
.values('name')
.dedup()
SPARQL (RDF) — Web semántica
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX org: <http://www.w3.org/ns/org#>
SELECT ?name WHERE {
?alice foaf:name "Alice" ;
foaf:knows ?friend .
?friend foaf:knows ?friend_of_friend .
?friend_of_friend org:memberOf ?company .
?company org:legalName "Google" .
?friend_of_friend foaf:name ?name .
}
Comparación de bases de datos de gráficos
| Característica | neo4j | Amazonas Neptuno | ArangoDB | JanusGraph | Dgrafo |
|---|---|---|---|---|---|
| Idioma de consulta | cifrar | Gremlin/SPARQL | AQL | duendecillo | GráficoQL+ |
| Almacenamiento | Gráfico nativo | RDF/Propiedad | Multimodelo | Casandra/HBase | tejón |
| Agrupación | Empresa | Gestionado | si | si | si |
| ÁCIDO | si | si | si | Por almacenamiento | si |
| Nivel gratuito | Comunidad (1 nodo) | Pago por uso | Código abierto | Código abierto | Código abierto |
| Mejor para | Gráficos empresariales | Ecosistema AWS | Multimodelo | Grandes gráficos de datos | Alto rendimiento |
| Búsqueda vectorial | ✅ (5.x+) | ❌ | ✅ | ❌ | ❌ |
Casos de uso
1. Redes Sociales y Recomendaciones
(User:Alice)-[:KNOWS]->(User:Bob)
(User:Alice)-[:LIKES]->(Movie:Inception)
(User:Bob)-[:LIKES]->(Movie:Inception)
(User:Charlie)-[:KNOWS]->(User:Alice)
Consulta de recomendación: "Películas que les gustan a los amigos de amigos":
MATCH (me:User {id: $userId})
-[:KNOWS*1..2]-
(other:User)
-[:LIKES]->
(movie:Movie)
WHERE NOT EXISTS {
(me)-[:LIKES]->(movie)
OR (me)-[:DISLIKES]->(movie)
}
RETURN movie.title, count(DISTINCT other) as friend_count,
avg(other.rating) as avg_rating
ORDER BY friend_count DESC, avg_rating DESC
LIMIT 20
2. Detección de fraude
Las redes de fraude exhiben patrones complejos y no obvios. Las consultas de gráficos las detectan de manera eficiente:
// Detect potential fraud rings:
// Multiple accounts sharing same device, IP, or phone
MATCH (account:Account)
-[:USED_DEVICE]->(device:Device)<-[:USED_DEVICE]-
(other:Account),
(account)-[:USED_IP]->(ip:IPAddress)<-[:USED_IP]-
(other)
WHERE account.id <> other.id
AND account.created_at > datetime() - duration('P7D')
RETURN account.id, other.id, device.device_id, ip.address,
count(*) as connection_count
ORDER BY connection_count DESC
LIMIT 100
Estadísticas de detección de fraude:
| Métrica | Antes del gráfico | Después del gráfico |
|---|---|---|
| Tasa de detección | 65% | 93% |
| Tasa de falsos positivos | 8% | 2% |
| Tiempo de investigación por caso | 45 minutos | 5 minutos |
3. Gráficos de conocimiento
Los gráficos de conocimiento conectan datos estructurados y no estructurados en una red unificada de significado:
// Create a knowledge graph from documents
LOAD CSV WITH HEADERS FROM 'file:///entities.csv' AS row
CREATE (e:Entity {
id: row.id,
name: row.name,
type: row.type,
description: row.description
});
LOAD CSV WITH HEADERS FROM 'file:///relationships.csv' AS row
MATCH (a:Entity {id: row.source_id})
MATCH (b:Entity {id: row.target_id})
CALL apoc.create.relationship(a, row.relationship_type, {
source_document: row.document,
confidence: toFloat(row.confidence)
}) YIELD rel
RETURN count(*);
// Query: "How does Product X relate to Regulation Y?"
MATCH path = shortestPath(
(product:Entity {name: "Product X"})
-[:AFFECTS|REGULATES|DEPENDS_ON|MANUFACTURED_BY*]-
(regulation:Entity {name: "Regulation Y"})
)
RETURN [node IN nodes(path) | {name: node.name, type: node.type}],
[rel IN relationships(path) | type(rel)]
4. Cadena de suministro
// Find all suppliers that feed into a critical component
MATCH (component:Part {name: "Critical Microchip"})
<-[:PRODUCES]-
(:Factory)
-[:SOURCES_FROM]->
(supplier:Supplier)
-[:SUPPLIED_BY]->
(sub_supplier:Supplier)
WHERE sub_supplier.location IN ["Region_A", "Region_B"]
RETURN component.name, supplier.name, sub_supplier.name,
sub_supplier.location
// Impact analysis: "If Supplier X fails, which products are affected?"
MATCH (failing:Supplier {id: $supplierId})
<-[:SUPPLIED_BY]-*
(factory:Factory)
-[:PRODUCES]->
(product:Product)
RETURN product.name, product.revenue,
count(DISTINCT factory) as factories_affected
ORDER BY product.revenue DESC
Componentes internos de la base de datos de gráficos
Adyacencia sin índice
La ventaja de rendimiento fundamental de las bases de datos de gráficos nativos: cada nodo apunta directamente a sus vecinos conectados. No se necesitan búsquedas de índice para los recorridos.
Relational Database: Graph Database:
┌────────┐
Find friends: │ Alice │──┐
1. Index lookup on person_id ──┐ │ │ │
2. Index lookup on friend_id ──┤ └────────┘ │
3. Join results ──┤ │ │
4. Fetch friend data ──┤ ┌──▼─────┐ │
│ │ Bob │◄─┘
O(log N) per hop │ │ │
│ └────────┘
│
For 6 degrees of separation: │ O(1) per traversal hop
O(log N × 6) = O(log N) │ O(6) = O(1)
│
│ For 6 hops: 6 pointer dereferences
Partición de gráficos
Para las bases de datos de gráficos distribuidos, la partición es un desafío:
| Estrategia | Descripción | problema |
|---|---|---|
| Corte de borde | Dividir por vértice, los bordes cruzan particiones | Muchos recorridos entre particiones |
| Corte de vértice | Dividido por arista, vértice replicado | Gastos generales de coherencia |
| Partición hash | Hash de vértices a particiones | Aleatorio: localidad pobre |
| División de rango | Partición por valor de propiedad | Sesgar si los datos no son uniformes |
Patrones de gráficos avanzados
Gráficos temporales (consultas de viajes en el tiempo)
// Property graph with versioned edges
MATCH (employee:Employee {id: $empId})
-[assignment:ASSIGNED_TO]->(project:Project)
WHERE assignment.from_date <= date("2026-01-15")
AND (assignment.to_date IS NULL OR assignment.to_date >= date("2026-01-15"))
RETURN employee.name, project.name, assignment.role
// What was the org structure on Jan 1, 2025?
MATCH (manager:Employee)
-[reports:MANAGES]->(report:Employee)
WHERE reports.effective_from <= date("2025-01-01")
AND (reports.effective_to IS NULL OR reports.effective_to > date("2025-01-01"))
RETURN manager.name, collect(report.name) as reports
Algoritmos de gráficos (Neo4j GDS)
from neo4j import GraphDatabase
from graphdatascience import GraphDataScience
gds = GraphDataScience("bolt://localhost:7687", auth=("neo4j", "password"))
# Create in-memory graph
G, result = gds.graph.project(
"myGraph",
["Person", "Company"],
["KNOWS", "WORKS_AT"]
)
# PageRank — find influential people
pagerank = gds.pageRank.stream(G)
influencers = pagerank.sort_values('score', ascending=False).head(10)
# Community detection (Louvain) — find clusters
communities = gds.louvain.stream(G)
Búsqueda gráfica + vectorial (híbrida)
Las bases de datos de gráficos modernas (Neo4j 5.x+) admiten búsqueda de gráficos y vectores:
// Find similar products using vector embeddings,
// then traverse the recommendation graph
CALL db.index.vector.queryNodes(
'product-embeddings',
10,
$query_embedding
) YIELD node AS similar_product, score
MATCH (similar_product)-[:ALSO_BOUGHT]->(recommended:Product)
WHERE recommended.rating > 4.0
RETURN recommended.name, recommended.price, score
ORDER BY score DESC, recommended.rating DESC
LIMIT 20
Antipatrones de bases de datos de gráficos
| Anti-patrón | Por qué duele | Mejor enfoque |
|---|---|---|
| Operaciones globales | MATCH (n) WHERE n.property escanea todos los nodos |
Agregar índice: CREAR ÍNDICE PARA (n:Etiqueta) EN (n.property) |
| Recorridos profundos e ilimitados | MATCH (a)-[*]->(b) sin límite |
Especificar profundidad: [*1..5] |
| Supernodos | Un nodo con millones de aristas | Dividase en nodos intermedios, utilice limites de tiempo |
| Falta dirección | Los bordes bidireccionales provocan un doble recorrido | Defina una dirección clara y recorra de manera eficiente |
| Sobrenormalización | Crear nodos para atributos simples | Utilice propiedades de nodo en su lugar |
Cuándo utilizar una base de datos de gráficos
Utilice el gráfico cuando:
- Las relaciones son de primera clase: las conexiones SON los datos.
- La profundidad del recorrido es variable: las consultas de 2 saltos frente a las de 6 saltos cambian dinámicamente.
- El esquema evoluciona con frecuencia: agrega nuevos tipos de relaciones sobre la marcha.
- La coincidencia de patrones es el patrón de consulta: "buscar rutas que se parezcan a X".
- Cadenas de unión complejas: más de 5 JOIN en SQL sugieren que un gráfico podría ser mejor.
No utilice gráficos cuando:
- Los datos son puramente tabulares: registros de ventas, registros de transacciones.
- Cargas de trabajo agregadas pesadas: "ingresos totales por región" (el almacén de columnas/SQL es mejor).
- CRUD simple por ID: "buscar usuario por correo electrónico" (la base de datos relacional está bien).
- Consultas puntuales de gran volumen: millones de búsquedas simples por segundo.
Conclusión
Las bases de datos de gráficos sobresalen cuando las relaciones son complejas, variables y centrales para el dominio. No reemplazan a las bases de datos relacionales: son una herramienta complementaria para espacios problemáticos específicos.
- Sistemas sociales y de recomendación: atraviesa gráficos de amigos de amigos de forma natural.
- Detección de fraude: encuentre conexiones no obvias en redes financieras.
- Gráficos de conocimiento: conecta datos de diversas fuentes en un modelo unificado.
- Cadena de suministro y logística: modele relaciones complejas de varios niveles.
- Operaciones de red y TI: gráficos de dependencia, análisis de causa raíz.
Mejores prácticas: Comience con Neo4j (el ecosistema más maduro), use Cypher para consultas y combínelo con la búsqueda vectorial para aplicaciones de gráficos impulsadas por IA. Mantenga limitadas las profundidades transversales, indexe las propiedades etiquetadas y supervise el crecimiento del supernodo.
Comentarios
0 comentariosTodavía no hay comentarios aprobados. Las respuestas nuevas pueden esperar moderación.