Artículo
Replicación de bases de datos y alta disponibilidad
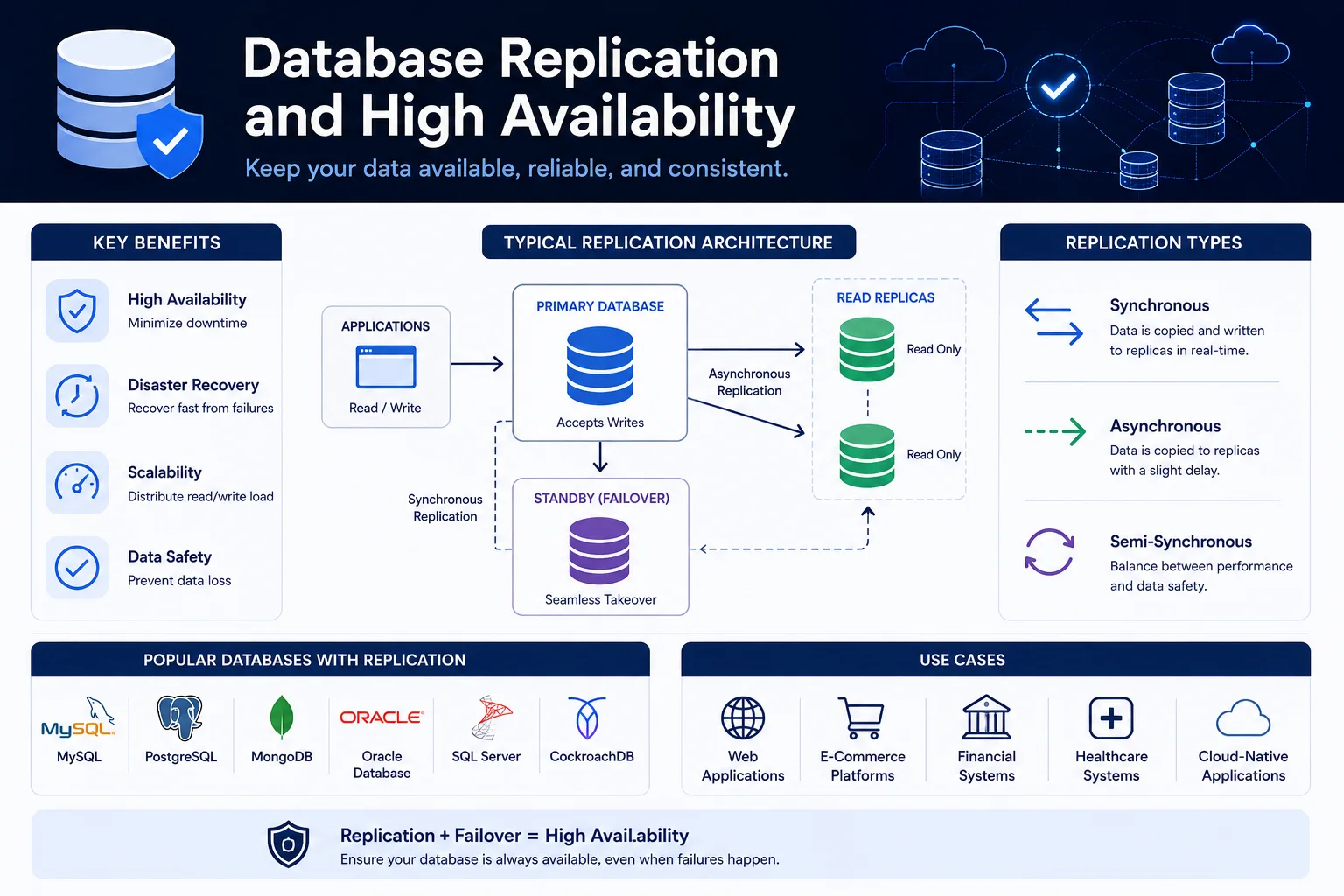
La replicación de bases de datos es el proceso de copiar y mantener datos de bases de datos en múltiples servidores. Es la base de la alta disponibilidad (HA), la recuperación ante desastres (DR), el escalado de lectura y la distribución geográfica.
4 min de lecturaIdioma: ES EspañolGratis0 aplausos0 comentarios
TecnologíaArtículos de ingenieríaDatabaseHighDatabasesTechnologyEngineering ArticlesReplication
Opciones de lectura
Introducción
La replicación de bases de datos es el proceso de copiar y mantener datos de bases de datos en múltiples servidores. Es la base de la alta disponibilidad (HA), la recuperación ante desastres (DR), el escalado de lectura y la distribución geográfica.
Ninguna base de datos está realmente "siempre activa": falla el hardware, se particiona la red, falla el software. La replicación garantiza que cuando falla una instancia de base de datos, otra pueda tomar el control con un tiempo de inactividad mínimo o nulo.
¿Por qué replicar?
| Objetivo | Descripción | Enfoque de replicación |
|---|---|---|
| Alta disponibilidad | El sistema permanece accesible después de fallas | Conmutación por error automática a réplica |
| Recuperación ante desastres | Sobrevivir a cortes a nivel regional | Réplicas georedundantes |
| Leer escala | Manejar más consultas de lectura | Distribuir lecturas a réplicas. |
| Copia de seguridad | Recuperación puntual sin carga | Réplica utilizada para copias de seguridad |
| Distribución geográfica | Baja latencia para usuarios globales | Réplicas locales en cada región. |
| Mantenimiento | Actualizaciones sin tiempo de inactividad | Conmutación por error durante el mantenimiento |
Arquitecturas de replicación
1. Líder único (Maestro-Réplica)
┌──────────────────┐
│ Master Node │
│ (reads + writes)│
└────────┬─────────┘
│ write-ahead log (WAL)
│
┌───────────────────┼───────────────────┐
│ │ │
┌────▼────┐ ┌────▼────┐ ┌────▼────┐
│Replica 1│ │Replica 2│ │Replica 3│
│(read │ │(read │ │(read │
│ only) │ │ only) │ │ only) │
└─────────┘ └─────────┘ └─────────┘
Ventajas:
- Sencillo de configurar y comprender.
- Lecturas consistentes del maestro.
- Bien respaldado por todas las bases de datos.
Contras:
- Escribir cuello de botella (maestro único).
- Retraso de replicación (asíncrono) o latencia de escritura (sincronización).
- Se necesita conmutación por error manual o automatizada.
-- PostgreSQL streaming replication setup
-- Primary: postgresql.conf
wal_level = replica
max_wal_senders = 10
wal_keep_size = 1024 -- MB
-- Replica: postgresql.conf
primary_conninfo = 'host=primary.example.com port=5432 user=replicator'
-- Create replication slot on primary
SELECT pg_create_physical_replication_slot('replica_1');
2. Multilíder (Activo-Activo)
┌──────────────┐ ┌──────────────┐
│ Leader A │◄───────────►│ Leader B │
│ (US-East) │ sync WAL │ (EU-West) │
└──────┬───────┘ └──────┬───────┘
│ │
┌────▼────┐ ┌────▼────┐
│Replica A│ │Replica B│
└─────────┘ └─────────┘
Ventajas:
- Se aceptan escrituras en múltiples ubicaciones (menor latencia).
- No hay un único punto de falla para las escrituras.
- Bueno para la distribución geográfica.
Contras:
- Los conflictos de escritura deben resolverse (el último escritor gana, CRDT, lógica de aplicación).
- Resolución de conflictos complejos.
- No todas las bases de datos admiten múltiples líderes.
# Multi-leader with conflict resolution (CouchDB, PostgreSQL BDR)
conflict_resolution:
strategy: "last_writer_wins" # Default — may lose data
# or: "application_merge" # Application handles conflicts
# or: "crdt" # Automatic conflict-free merging
3. Sin líder (basado en quórum)
Client ──► Write to all 3 nodes (W=2, R=2)
┌────────┐ ┌────────┐ ┌────────┐
│ Node 1 │ │ Node 2 │ │ Node 3 │
└────────┘ └────────┘ └────────┘
│ │ │
└─────────────┼─────────────┘
│
Client ◄────── Read from 2 nodes, compare versions (R=2)
Modelo de Amazon DynamoDB/Cassandra:
- Cualquier nodo puede aceptar lecturas o escrituras.
- W + R > N (nodos totales) garantiza la coherencia.
- Utiliza relojes vectoriales para el seguimiento de versiones.
Ventajas:
- No hay un único punto de fracaso.
- Disponibilidad extremadamente alta.
- Escalabilidad lineal.
Contras:
- Coherencia final por defecto.
- Resolución de conflictos complejos (relojes vectoriales).
- No apto para datos relacionales con claves foráneas.
Replicación síncrona versus asincrónica
| Aspecto | sincrónico | Asíncrono |
|---|---|---|
| Pérdida de datos en caso de conmutación por error | Cero (RPO = 0) | Alguna pérdida de datos (RPO > 0) |
| Latencia de escritura | Superior (esperar réplica ACK) | Bajar (confirmar inmediatamente) |
| Coherencia lectura tras escritura | Garantizado | Posiblemente lecturas obsoletas de la réplica |
| Requisito de red | Baja latencia, confiable | Tolera una mayor latencia |
| Impacto de réplica | La falla de la réplica bloquea las escrituras | El error de la réplica no tiene ningún impacto |
-- PostgreSQL: synchronous replication
-- primary.conf
synchronous_standby_names = 'FIRST 1 (replica_1, replica_2)'
-- Now every write waits for at least one synchronous replica
-- Acknowledgment before returning COMMIT to client
Estrategias de conmutación por error
Conmutación por error manual
# PostgreSQL manual failover
# On replica:
pg_ctl promote -D /var/lib/postgresql/data
# Update application connection string
# point at new primary
Tiempo de inactividad: Minutos a horas (tiempo de respuesta humana).
Conmutación por error automática (herramientas HA)
# Patroni — PostgreSQL HA
scope: production
namespace: /db/
consul:
host: consul.example.com:8500
postgresql:
use_pg_rewind: true
parameters:
max_connections: 200
# On primary failure:
# 1. Patroni detects primary is down
# 2. Promotes most up-to-date replica
# 3. Updates Consul with new primary address
# 4. All clients automatically reconnect
| Herramienta | Base de datos | Mecanismo | Tiempo de conmutación por error |
|---|---|---|---|
| Patronos | PostgreSQL | Cónsul/etcd + API REST | 10-30 segundos |
| Orquestador | mysql | Basado en balsa | 5-15 segundos |
| Centinela Redis | Redis | Protocolo de chismes | 10-30 segundos |
| Conjunto de réplicas de MongoDB | MongoDB | Elección interna | < 10 segundos |
| Operador Kubernetes | Varios | K8s-nativo | Depende de la sonda |
Conmutación por error VIP/DNS
# Keepalived — Virtual IP failover
vrrp_instance VI_1 {
interface eth0
state BACKUP
virtual_router_id 51
priority 100
advert_int 1
virtual_ipaddress {
10.0.0.100/24 # Floating IP
}
track_script {
chk_postgres
}
}
Retraso y coherencia de la replicación
Causas del retraso en la replicación
| causa | Descripción | Mitigación |
|---|---|---|
| Latencia de red | Distancia entre nodos | Colocar o utilizar optimización WAN |
| Grandes transacciones | Lento para aplicar en la réplica | Divida en transacciones más pequeñas |
| saturación de CPU | La réplica no puede seguir el ritmo | Hardware de réplica a escala |
| Consultas de larga duración | Cerraduras en réplica | Establecer tiempo de espera de declaración |
| Operaciones DDL | El esquema cambia las tablas de bloqueo | Usar DDL concurrente |
Monitoreo del retraso de replicación
-- PostgreSQL lag monitoring
SELECT application_name,
pg_size_pretty(pg_wal_lsn_diff(
pg_current_wal_lsn(), replay_lsn
)) as lag_bytes,
ROUND(EXTRACT(EPOCH FROM NOW() - pg_last_xact_replay_timestamp()))
as lag_seconds
FROM pg_stat_replication;
-- Expected: < 1 second (async), < 10ms (sync)
Manejo de lecturas obsoletas
# Application pattern: "read-your-writes" consistency
class ConsistentDBClient:
def __init__(self, master, replica):
self.master = master
self.replica = replica
def write(self, key, value):
# Write to master, record timestamp
result = self.master.execute("INSERT ...")
self._last_write_timestamp = time.time()
return result
def read(self, key):
# Read from replica, but verify freshness
data = self.replica.execute(f"SELECT * FROM ... WHERE id='{key}'")
# Check if we just wrote this record
stale_time = time.time() - self._last_write_timestamp
if stale_time < 1.0: # Within last second
# This is a recent write — read from master for consistency
if data is None:
data = self.master.execute(f"SELECT ... WHERE id='{key}'")
return data
Copia de seguridad y recuperación ante desastres
Estrategias de respaldo
| Estrategia | RPO | RTO | Almacenamiento | Costo |
|---|---|---|---|---|
| Copia de seguridad completa diaria | 24 horas | Horas | Alto | Bajo |
| Archivo WAL | Minutos | variable | Medio | Bajo |
| Archivo continuo | < 1 minuto | Minutos | Alto | Medio |
| Réplica para respaldo | Segundos | Rápido | Alto | Medio |
| Réplica multirregional | < 1 segundo | Más rápido | muy alto | Alto |
# PostgreSQL continuous archiving
archive_mode = on
archive_command = 'pgbackrest --stanza=prod archive-push %p'
# Point-in-time recovery
pgbackrest --stanza=prod --type=time \
--target="2026-05-24 14:30:00+00" \
--target-action=promote restore
Niveles de recuperación ante desastres
RPO: Recovery Point Objective (how much data can you lose)
RTO: Recovery Time Objective (how fast must you recover)
Tier 1 (Mission Critical): RPO < 1 minute, RTO < 5 minutes
Multi-region synchronous replication
Automatic failover
Regularly tested
Tier 2 (Business Critical): RPO < 1 hour, RTO < 30 minutes
Async replication to DR region
Semi-automated failover
Quarterly tests
Tier 3 (Standard): RPO < 24 hours, RTO < 4 hours
Daily backups + WAL archiving
Manual restore
Annual tests
Leer escalado con réplicas
Lecturas de equilibrio de carga
import random
from itertools import cycle
class ReadLoadBalancer:
def __init__(self, replicas: list[str]):
self.replicas = cycle(replicas)
def get_reader(self) -> str:
return next(self.replicas)
def execute_query(self, query: str, is_read: bool = True):
if is_read:
conn = self.get_reader()
else:
conn = "master"
return execute_on(conn, query)
Equilibrio de carga basado en proxy
# PgBouncer or HAProxy configuration
# Routes reads to replicas, writes to master
listen pg_cluster
bind *:5432
mode tcp
acl is_write method POST
acl is_write query ^(INSERT|UPDATE|DELETE)
use_backend master if is_write
default_backend replicas
backend master
server pg-master 10.0.0.1:5432 check
backend replicas
server pg-replica1 10.0.0.2:5432 check
server pg-replica2 10.0.0.3:5432 check
server pg-replica3 10.0.0.4:5432 check
Replicación específica de bases de datos
PostgreSQL
| Característica | Descripción |
|---|---|
| Replicación en streaming | Transmisión física de WAL a réplicas |
| Replicación lógica | Replicación a nivel de tabla (PostgreSQL 10+) |
| Replicación en cascada | La réplica puede servir a otras réplicas. |
| Replicación sincrónica | Sincronización configurable por transacción |
| pg_rewind | Resincronización rápida después de la división del cerebro |
mysql
| Característica | Descripción |
|---|---|
| Replicación grupal | Membresía de grupo integrada y multimaestro |
| Clúster InnoDB | Solución HA completa con MySQL Router |
| Replicación semisincronizada | Al menos una réplica reconoce |
| Replicación basada en GTID | ID de transacciones globales para mayor seguridad |
MongoDB
| Característica | Descripción |
|---|---|
| Conjunto de réplicas | Elección automática, hasta 50 miembros. |
| Escribe inquietud | Nivel de reconocimiento configurable |
| Preferencia de lectura | Lecturas de ruta a la réplica más cercana |
| Cambiar secuencias | CDC en tiempo real desde oplog |
Problema del cerebro dividido
El cerebro dividido ocurre cuando la partición de la red hace que ambos nodos crean que son el maestro:
Before partition:
Master A ◄──► Replica B
After partition:
Master A |X| Replica B (promoted to master)
(believes it |X| (believes it is master)
is master) |X|
When partition heals: two masters, inconsistent data
Prevención:
- Quórum mayoritario: solo el lado con > N/2 nodos puede ser maestro.
- STONITH (Dispara al otro nodo en la cabeza) — Mata al viejo maestro.
- Vallas: revocar el acceso al almacenamiento compartido.
- Basado en contrato de arrendamiento: el contrato de arrendamiento vence y debe renovarse.
Conclusión
La replicación de bases de datos es esencial para los sistemas de producción que requieren disponibilidad, durabilidad y rendimiento:
| Escala | Enfoque |
|---|---|
| Pequeño (nodo único) | Copias de seguridad diarias en S3 |
| Medio (1-10 millones de usuarios) | Maestro único + 1 o 2 réplicas, conmutación por error automatizada |
| Grande (10-100 millones de usuarios) | Multilíder o fragmentado, distribuido geográficamente |
| Global (más de 100 millones de usuarios) | Activo-activo multirregional, CRDT o ganador del último escritor |
Principios clave:
- Prueba de conmutación por error: si no lo has probado, no funciona.
- Retraso del monitor: el retraso en la replicación es la fuente más común de inconsistencia de los datos.
- Planifique el cerebro dividido: tenga una estrategia antes de que suceda.
- Haga coincidir RPO/RTO con las necesidades empresariales: no todos los sistemas necesitan cero pérdida de datos.
- Automatiza todo: la recuperación manual genera errores y tiempo de inactividad.
La replicación no es una característica que se configura y se olvida: requiere monitoreo, pruebas y optimización continuos.
Comentarios
0 comentariosTodavía no hay comentarios aprobados. Las respuestas nuevas pueden esperar moderación.