Makale
Veritabanı Çoğaltma ve Yüksek Erişilebilirlik
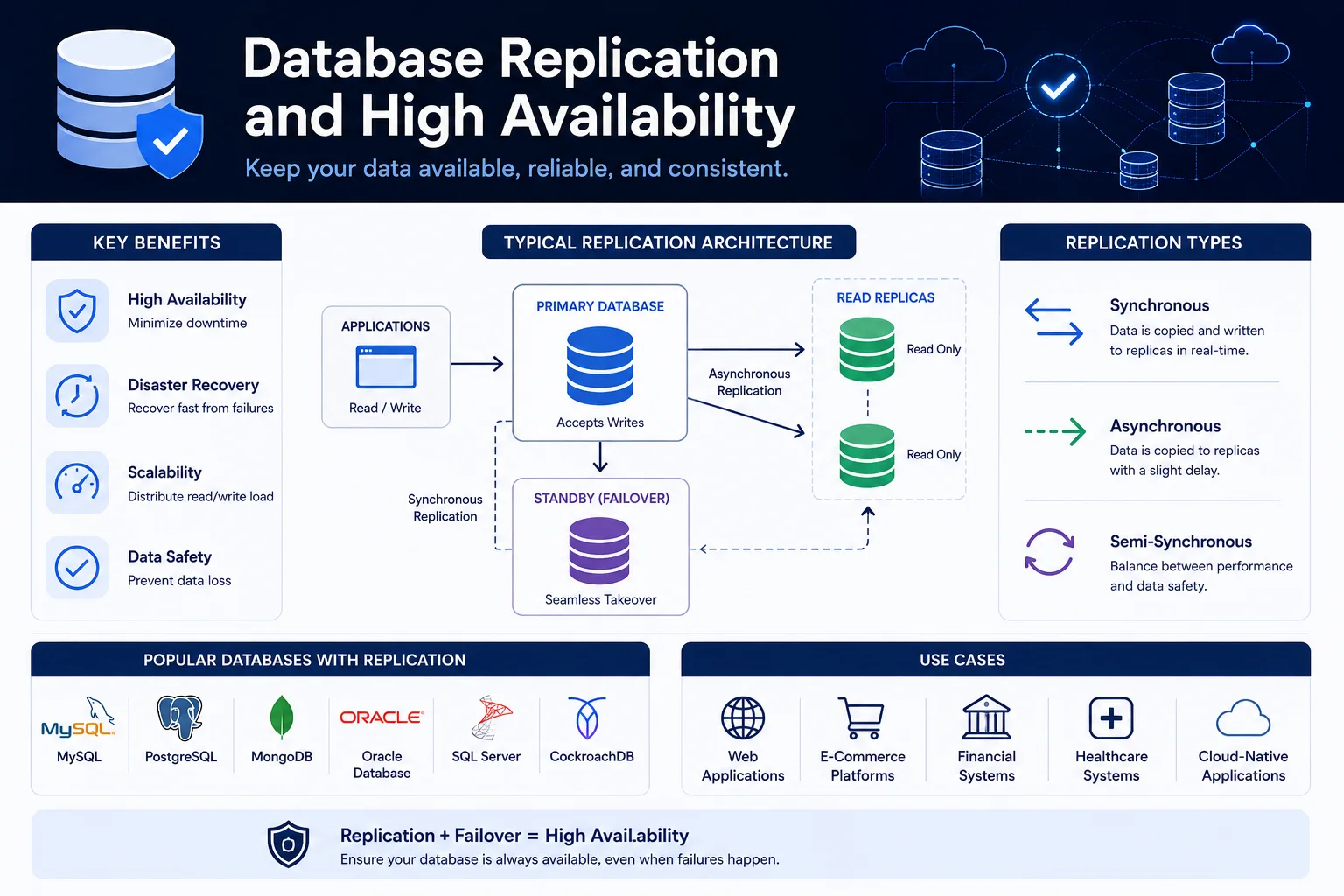
Veritabanı çoğaltma, veritabanı verilerinin birden fazla sunucuya kopyalanması ve sürdürülmesi işlemidir. Yüksek kullanılabilirliğin (HA), olağanüstü durum kurtarmanın (DR), okuma ölçeklendirmesinin ve coğrafi dağıtımın temelidir.
4 dk okumaDil: TR TürkçeÜcretsiz0 alkış0 yorum
TeknolojiMühendislik MakaleleriDatabaseHighDatabasesTechnologyEngineering ArticlesReplication
Okuma seçenekleri
Giriş
Veritabanı çoğaltma, veritabanı verilerinin birden fazla sunucuya kopyalanması ve sürdürülmesi işlemidir. Yüksek kullanılabilirliğin (HA), olağanüstü durum kurtarmanın (DR), okuma ölçeklendirmesinin ve coğrafi dağıtımın temelidir.
Hiçbir veritabanı gerçekten "her zaman çalışır durumda" değildir; donanım arızaları, ağ bölümleri, yazılım çökmeleri. Çoğaltma, bir veritabanı örneğinin başarısız olması durumunda, en az kesinti süresiyle veya hiç kesinti olmadan bir başkasının görevi devralmasını sağlar.
Neden Çoğaltma?
| Amaç | Açıklama | Replikasyon Yaklaşımı |
|---|---|---|
| Yüksek Kullanılabilirlik | Arızalardan sonra sistem erişilebilir kalır | Çoğaltmaya otomatik yük devretme |
| Olağanüstü Durum Kurtarma | Bölge düzeyindeki kesintilerden kurtulun | Coğrafi olarak yedekli kopyalar |
| Ölçeklendirmeyi Oku | Daha fazla okuma sorgusunu yönetin | Okumaları kopyalara dağıtma |
| Yedekleme | Yük olmadan belirli bir zamanda kurtarma | Yedeklemeler için kullanılan kopya |
| Coğrafi Dağılım | Küresel kullanıcılar için düşük gecikme süresi | Her bölgedeki yerel kopyalar |
| Bakım | Sıfır kesinti süreli yükseltmeler | Bakım sırasında arıza |
Çoğaltma Mimarileri
1. Tek Lider (Ana-Çoğaltma)
┌──────────────────┐
│ Master Node │
│ (reads + writes)│
└────────┬─────────┘
│ write-ahead log (WAL)
│
┌───────────────────┼───────────────────┐
│ │ │
┌────▼────┐ ┌────▼────┐ ┌────▼────┐
│Replica 1│ │Replica 2│ │Replica 3│
│(read │ │(read │ │(read │
│ only) │ │ only) │ │ only) │
└─────────┘ └─────────┘ └─────────┘
Artıları:
- Kurulumu ve anlaşılması basit.
- Ustadan tutarlı okumalar.
- Tüm veritabanları tarafından iyi desteklenir.
Eksileri:
- Darboğaz yazın (tek yönetici).
- Çoğaltma gecikmesi (eşzamansız) veya yazma gecikmesi (senkronizasyon).
- Manuel veya otomatik yük devretme gerekli.
-- PostgreSQL streaming replication setup
-- Primary: postgresql.conf
wal_level = replica
max_wal_senders = 10
wal_keep_size = 1024 -- MB
-- Replica: postgresql.conf
primary_conninfo = 'host=primary.example.com port=5432 user=replicator'
-- Create replication slot on primary
SELECT pg_create_physical_replication_slot('replica_1');
2. Çoklu Lider (Aktif-Aktif)
┌──────────────┐ ┌──────────────┐
│ Leader A │◄───────────►│ Leader B │
│ (US-East) │ sync WAL │ (EU-West) │
└──────┬───────┘ └──────┬───────┘
│ │
┌────▼────┐ ┌────▼────┐
│Replica A│ │Replica B│
└─────────┘ └─────────┘
Artıları:
- Birden fazla konumda kabul edilen yazmalar (daha düşük gecikme).
- Yazma işlemleri için tek bir hata noktası yoktur.
- Coğrafi dağılım için iyidir.
Eksileri:
- Yazma çakışmalarının çözülmesi gerekir (son yazan kazanır, CRDT'ler, uygulama mantığı).
- Karmaşık çatışma çözümü.
- Tüm veritabanları çoklu lideri desteklemez.
# Multi-leader with conflict resolution (CouchDB, PostgreSQL BDR)
conflict_resolution:
strategy: "last_writer_wins" # Default — may lose data
# or: "application_merge" # Application handles conflicts
# or: "crdt" # Automatic conflict-free merging
3. Lidersiz (Çoğunluğa Dayalı)
Client ──► Write to all 3 nodes (W=2, R=2)
┌────────┐ ┌────────┐ ┌────────┐
│ Node 1 │ │ Node 2 │ │ Node 3 │
└────────┘ └────────┘ └────────┘
│ │ │
└─────────────┼─────────────┘
│
Client ◄────── Read from 2 nodes, compare versions (R=2)
Amazon DynamoDB / Cassandra modeli:
- Herhangi bir düğüm okuma veya yazma işlemlerini kabul edebilir.
- W + R > N (toplam düğümler) tutarlılığı garanti eder.
- Sürüm takibi için vektör saatlerini kullanır.
Artıları:
- Tek bir başarısızlık noktası yok.
- Son derece yüksek kullanılabilirlik.
- Doğrusal ölçeklenebilirlik.
Eksileri:
- Varsayılan olarak nihai tutarlılık.
- Karmaşık çakışma çözümü (vektör saatleri).
- Yabancı anahtarlara sahip ilişkisel veriler için uygun değildir.
Eşzamanlı ve Eşzamansız Çoğaltma
| Görünüş | Senkron | Asenkron |
|---|---|---|
| Yük devretme sırasında veri kaybı | Sıfır (RPO = 0) | Bir miktar veri kaybı (RPO > 0) |
| Yazma gecikmesi | Daha yüksek (ACK kopyasını bekleyin) | İndirin (hemen onaylayın) |
| Yazma sonrası okuma tutarlılığı | Garantili | Kopyadan muhtemelen eski okumalar |
| Ağ gereksinimi | Düşük gecikme süresi, güvenilir | Daha yüksek gecikmeyi tolere eder |
| Kopya etkisi | Çoğaltma hatası blokları yazma | Çoğaltma hatasının hiçbir etkisi yoktur |
-- PostgreSQL: synchronous replication
-- primary.conf
synchronous_standby_names = 'FIRST 1 (replica_1, replica_2)'
-- Now every write waits for at least one synchronous replica
-- Acknowledgment before returning COMMIT to client
Yük Devretme Stratejileri
Manuel Yük Devretme
# PostgreSQL manual failover
# On replica:
pg_ctl promote -D /var/lib/postgresql/data
# Update application connection string
# point at new primary
Kesinti süresi: Dakikalardan saatlere kadar (insan müdahale süresi).
Otomatik Yük Devretme (HA Araçları)
# Patroni — PostgreSQL HA
scope: production
namespace: /db/
consul:
host: consul.example.com:8500
postgresql:
use_pg_rewind: true
parameters:
max_connections: 200
# On primary failure:
# 1. Patroni detects primary is down
# 2. Promotes most up-to-date replica
# 3. Updates Consul with new primary address
# 4. All clients automatically reconnect
| Araç | Veritabanı | Mekanizma | Yük Devretme Süresi |
|---|---|---|---|
| Patroni | PostgreSQL | Konsolos/etcd + REST API | 10-30 saniye |
| Orkestratör | MySQL | Sal tabanlı | 5-15 saniye |
| Redis Sentinel | Redis | Dedikodu protokolü | 10-30 saniye |
| MongoDB Çoğaltma Seti | MongoDB | İç seçim | < 10 saniye |
| Kubernetes Operatörü | Çeşitli | K8s-yerli | Proba bağlıdır |
VIP / DNS Yük Devretme
# Keepalived — Virtual IP failover
vrrp_instance VI_1 {
interface eth0
state BACKUP
virtual_router_id 51
priority 100
advert_int 1
virtual_ipaddress {
10.0.0.100/24 # Floating IP
}
track_script {
chk_postgres
}
}
Çoğaltma Gecikmesi ve Tutarlılığı
Çoğaltma Gecikmesinin Nedenleri
| Sebep | Açıklama | Azaltma |
|---|---|---|
| Ağ gecikmesi | Düğümler arasındaki mesafe | WAN optimizasyonunu birlikte konumlandırın veya kullanın |
| Büyük işlemler | Çoğaltmada uygulanması yavaş | Daha küçük işlemlere bölün |
| CPU doygunluğu | Replika yetişemiyor | Çoğaltma donanımını ölçeklendirin |
| Uzun süren sorgular | Replikadaki kilitler | statement_timeout'u ayarla |
| DDL işlemleri | Şema kilit tablolarını değiştirir | Eşzamanlı DDL kullan |
Çoğaltma Gecikmesini İzleme
-- PostgreSQL lag monitoring
SELECT application_name,
pg_size_pretty(pg_wal_lsn_diff(
pg_current_wal_lsn(), replay_lsn
)) as lag_bytes,
ROUND(EXTRACT(EPOCH FROM NOW() - pg_last_xact_replay_timestamp()))
as lag_seconds
FROM pg_stat_replication;
-- Expected: < 1 second (async), < 10ms (sync)
Eski Okumaları İşleme
# Application pattern: "read-your-writes" consistency
class ConsistentDBClient:
def __init__(self, master, replica):
self.master = master
self.replica = replica
def write(self, key, value):
# Write to master, record timestamp
result = self.master.execute("INSERT ...")
self._last_write_timestamp = time.time()
return result
def read(self, key):
# Read from replica, but verify freshness
data = self.replica.execute(f"SELECT * FROM ... WHERE id='{key}'")
# Check if we just wrote this record
stale_time = time.time() - self._last_write_timestamp
if stale_time < 1.0: # Within last second
# This is a recent write — read from master for consistency
if data is None:
data = self.master.execute(f"SELECT ... WHERE id='{key}'")
return data
Yedekleme ve Felaket Kurtarma
Yedekleme Stratejileri
| Strateji | RPO | RTO | Depolama | Maliyet |
|---|---|---|---|---|
| Günlük tam yedekleme | 24 saat | Saatler | Yüksek | Düşük |
| WAL arşivleme | dakika | Değişken | Orta | Düşük |
| Sürekli arşivleme | < 1 dakika | dakika | Yüksek | Orta |
| Yedekleme için kopya | Saniye | Hızlı | Yüksek | Orta |
| Çok bölgeli çoğaltma | < 1 saniye | En hızlı | Çok yüksek | Yüksek |
# PostgreSQL continuous archiving
archive_mode = on
archive_command = 'pgbackrest --stanza=prod archive-push %p'
# Point-in-time recovery
pgbackrest --stanza=prod --type=time \
--target="2026-05-24 14:30:00+00" \
--target-action=promote restore
Olağanüstü Durum Kurtarma Katmanları
RPO: Recovery Point Objective (how much data can you lose)
RTO: Recovery Time Objective (how fast must you recover)
Tier 1 (Mission Critical): RPO < 1 minute, RTO < 5 minutes
Multi-region synchronous replication
Automatic failover
Regularly tested
Tier 2 (Business Critical): RPO < 1 hour, RTO < 30 minutes
Async replication to DR region
Semi-automated failover
Quarterly tests
Tier 3 (Standard): RPO < 24 hours, RTO < 4 hours
Daily backups + WAL archiving
Manual restore
Annual tests
Kopyalarla Ölçeklendirmeyi Okuyun
Yük Dengeleme Okumaları
import random
from itertools import cycle
class ReadLoadBalancer:
def __init__(self, replicas: list[str]):
self.replicas = cycle(replicas)
def get_reader(self) -> str:
return next(self.replicas)
def execute_query(self, query: str, is_read: bool = True):
if is_read:
conn = self.get_reader()
else:
conn = "master"
return execute_on(conn, query)
Proxy Tabanlı Yük Dengeleme
# PgBouncer or HAProxy configuration
# Routes reads to replicas, writes to master
listen pg_cluster
bind *:5432
mode tcp
acl is_write method POST
acl is_write query ^(INSERT|UPDATE|DELETE)
use_backend master if is_write
default_backend replicas
backend master
server pg-master 10.0.0.1:5432 check
backend replicas
server pg-replica1 10.0.0.2:5432 check
server pg-replica2 10.0.0.3:5432 check
server pg-replica3 10.0.0.4:5432 check
Veritabanına Özel Çoğaltma
PostgreSQL
| Özellik | Açıklama |
|---|---|
| Akış çoğaltma | Replikalara fiziksel WAL akışı |
| Mantıksal çoğaltma | Tablo düzeyinde çoğaltma (PostgreSQL 10+) |
| Basamaklı çoğaltma | Replika diğer replikalara hizmet edebilir |
| Eşzamanlı çoğaltma | İşlem başına yapılandırılabilir senkronizasyon |
| pg_rewind | Bölünmüş beyinden sonra hızlı yeniden senkronizasyon |
MySQL
| Özellik | Açıklama |
|---|---|
| Grup Çoğaltma | Çoklu yönetici, yerleşik grup üyeliği |
| InnoDB Kümesi | MySQL Router ile eksiksiz HA çözümü |
| Yarı senkronize çoğaltma | En az bir kopya onaylıyor |
| GTID tabanlı çoğaltma | Güvenlik için küresel işlem kimlikleri |
MongoDB
| Özellik | Açıklama |
|---|---|
| Kopya Seti | Otomatik seçim, 50 üyeye kadar |
| Endişenizi yazın | Yapılandırılabilir onay düzeyi |
| Tercihi okuyun | Rota en yakın kopyaya okur |
| Akışları değiştir | Oplog'dan gerçek zamanlı CDC |
Bölünmüş Beyin Sorunu
Bölünmüş beyin, ağ bölümü her iki düğümün de kendilerinin ana olduğuna inanmasına neden olduğunda ortaya çıkar:
Before partition:
Master A ◄──► Replica B
After partition:
Master A |X| Replica B (promoted to master)
(believes it |X| (believes it is master)
is master) |X|
When partition heals: two masters, inconsistent data
Önleme:
- Çoğunluk yeter sayısı — Yalnızca > N/2 düğüme sahip olan taraf ana olabilir.
- STONITH (Diğer Düğümü Kafasından Vur) — Eski ustayı öldür.
- Eskrim — Paylaşılan depolama alanına erişimi iptal edin.
- Kiralamaya dayalı — Kira sözleşmesinin süresi dolar ve yenilenmesi gerekir.
Sonuç
Kullanılabilirlik, dayanıklılık ve performans gerektiren üretim sistemleri için veritabanı çoğaltma önemlidir:
| Ölçek | Yaklaşım |
|---|---|
| Küçük (tek düğüm) | S3'e günlük yedeklemeler |
| Orta (1-10 milyon kullanıcı) | Tek ana + 1-2 kopya, otomatik yük devretme |
| Büyük (10-100 milyon kullanıcı) | Çok liderli veya parçalı, coğrafi olarak dağıtılmış |
| Dünya çapında (100 milyondan fazla kullanıcı) | Çok bölgeli aktif-aktif, CRDT'ler veya son yazarın kazanması |
Temel ilkeler:
- Yük devretme testi — Test etmediyseniz çalışmaz.
- Monitör gecikmesi — Çoğaltma gecikmesi, veri tutarsızlığının en yaygın kaynağıdır.
- Bölünmüş beyin için plan yapın — Bu gerçekleşmeden önce bir stratejiniz olsun.
- RPO/RTO'yu iş gereksinimleriyle eşleştirin — Her sistemin sıfır veri kaybına ihtiyacı yoktur.
- Her şeyi otomatikleştirin — Manuel kurtarma, hatalara ve kesintilere yol açar.
Çoğaltma, kur ve unut özelliği değildir; sürekli izleme, test etme ve optimizasyon gerektirir.
Yorumlar
0 yorumHenüz onaylı yorum yok. Yeni yanıtlar moderasyon bekleyebilir.