Article
Microservices Architecture
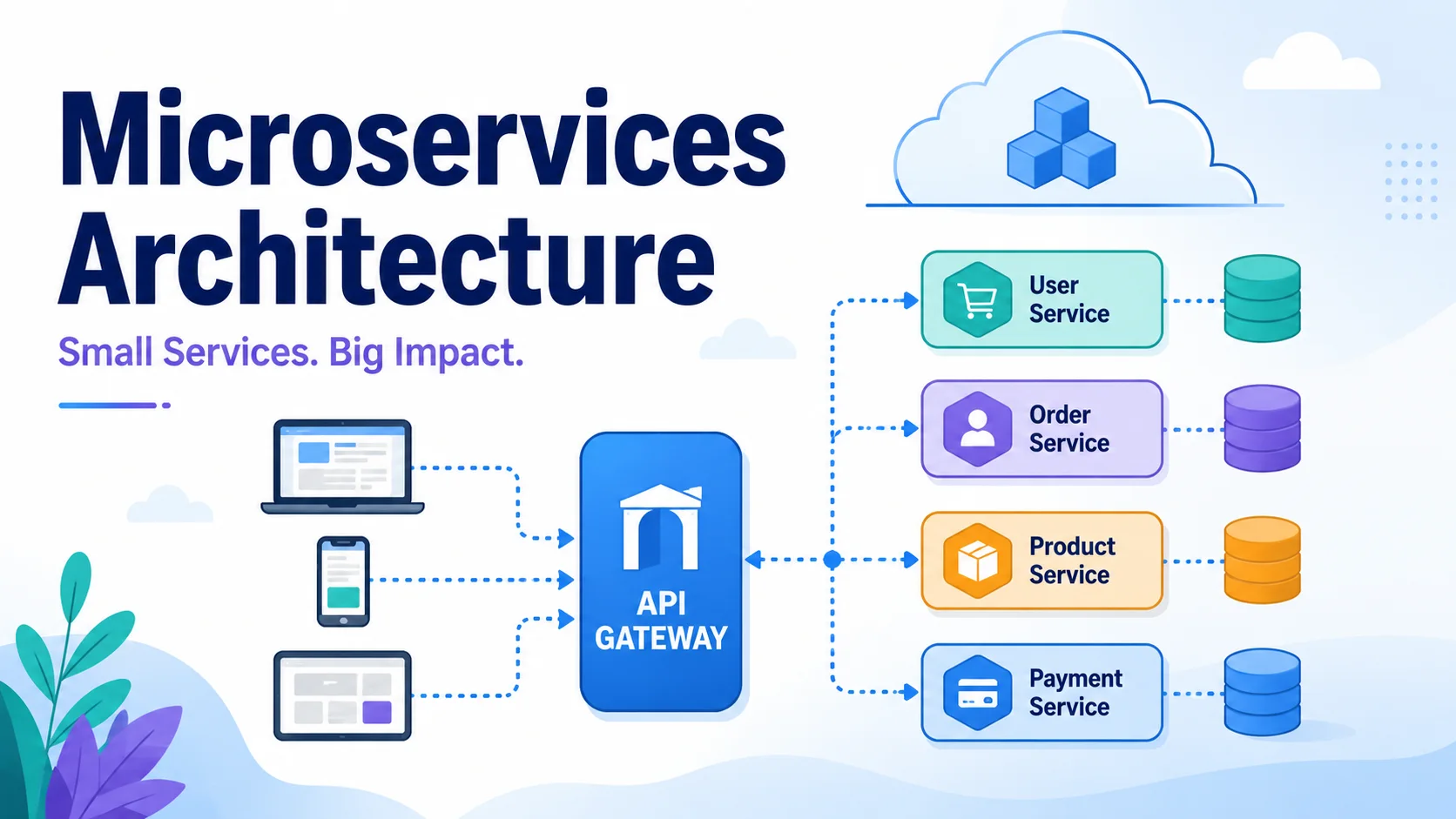
Microservices architecture structures an application as a collection of loosely coupled, independently deployable services. Each service owns a specific business capability, has its own data store, and communicates over a network. While microservices introduce significant operational complexity, they enable organizations to scale development teams, deploy independently, and build more resilient systems.
5 min readLanguage: EN EnglishFree0 claps0 comments
TechnologyEngineering ArticlesDevOpsArchitectureMicroservicesTechnologyEngineering Articles
Reading options
Introduction
Microservices architecture structures an application as a collection of loosely coupled, independently deployable services. Each service owns a specific business capability, has its own data store, and communicates over a network. While microservices introduce significant operational complexity, they enable organizations to scale development teams, deploy independently, and build more resilient systems.
Monolith vs. Microservices
The Monolith
A monolithic application has all functionality in a single codebase and deployment unit:
┌─────────────────────────────────────────────┐
│ Monolith Application │
├──────────────┬──────────────┬───────────────┤
│ User Module │ Order Module│ Payment │
│ (controllers, services, repos, DB tables) │
└──────────────┴──────────────┴───────────────┘
Monolith advantages:
- Simple development and testing (single process).
- Easy debugging (no network calls between modules).
- Fast communication (in-memory method calls).
- No distributed system complexity.
- Ideal for small teams and early-stage products.
Monolith disadvantages:
- Scaling means scaling everything, not just the bottleneck.
- A single bug can crash the entire application.
- Technology stack is locked in.
- Large codebase becomes hard to understand and maintain.
- Deployment takes longer as codebase grows.
- Team coordination overhead increases.
The Microservices Architecture
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ User Service │ │ Order Service │ │ Payment Service │
│ (own DB, API) │ │ (own DB, API) │ │ (own DB, API) │
└────────┬─────────┘ └────────┬─────────┘ └────────┬─────────┘
│ │ │
└──────────────────────┼──────────────────────┘
│
┌───────────▼───────────┐
│ API Gateway │
│ (auth, routing) │
└───────────────────────┘
Core Principles
1. Single Responsibility
Each service owns exactly one business capability. If you can describe a service's purpose without using "and," it is likely well-scoped.
Good:
payment-service— Handles payment processing and refunds.notification-service— Sends emails, SMS, and push notifications.inventory-service— Manages stock levels and reservations.
Bad:
user-and-order-service— Two distinct capabilities combined (violates SRP).backend-service— Everything in one service (not microservices at all).
2. Decentralized Data Management
Each service owns its database. Services never share databases — they communicate through APIs.
-- Service A has its own database
CREATE TABLE users (
id UUID PRIMARY KEY,
email VARCHAR(255) UNIQUE,
name VARCHAR(255)
);
-- Service B has its own database, stores only the user ID
CREATE TABLE orders (
id UUID PRIMARY KEY,
user_id UUID NOT NULL,
total DECIMAL(10,2),
status VARCHAR(50)
);
Why not share databases?
- Tight coupling — schema changes in one service break others.
- Different services have different storage needs (relational vs. document vs. graph).
- Independent deployment becomes impossible.
- Scaling requires coordinated schema migrations.
3. Resilience and Fault Isolation
A failure in one service should not cascade to others.
Circuit Breaker Pattern:
// Using a circuit breaker to handle service failures gracefully
const breaker = new CircuitBreaker({
failureThreshold: 5,
resetTimeout: 30000, // 30 seconds
});
async function getPaymentStatus(orderId: string) {
try {
return await breaker.call(() => paymentService.getStatus(orderId));
} catch (error) {
// Fallback: return cached status or default
return { status: 'pending', note: 'Payment service unavailable' };
}
}
Bulkhead Pattern: Allocate separate thread pools for different services so one slow service does not exhaust all resources:
// Separate thread pools per service
const paymentPool = new ThreadPool({ maxThreads: 10 });
const inventoryPool = new ThreadPool({ maxThreads: 20 });
const notificationPool = new ThreadPool({ maxThreads: 5 });
4. Independent Deployability
Each service can be deployed independently. This is the primary benefit of microservices.
Deployment automation:
# GitHub Actions for a single microservice
name: Deploy Payment Service
on:
push:
paths:
- 'services/payment/**'
- '.github/workflows/payment.yml'
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: docker build -t payment-service .
- run: docker push registry.example.com/payment-service:${{ github.sha }}
- run: kubectl set image deployment/payment-service payment-service=registry.example.com/payment-service:${{ github.sha }}
Communication Patterns
Synchronous Communication (REST, gRPC)
Pros: Simple to implement and reason about. Request-response semantics are familiar.
Cons: Creates runtime coupling — if the downstream service is down, the caller is affected.
// REST call using fetch
const order = await fetch(`http://order-service:8080/api/orders/${orderId}`);
// gRPC definition
service OrderService {
rpc GetOrder (GetOrderRequest) returns (Order);
}
message GetOrderRequest {
string order_id = 1;
}
Asynchronous Communication (Message Queues)
Pros: Loose coupling, better resilience, supports event-driven architectures.
Cons: Eventual consistency, harder to debug, requires message infrastructure.
// Kafka producer
await producer.send({
topic: 'order.created',
messages: [{ value: JSON.stringify({ orderId, userId, total }) }]
});
// Kafka consumer in notification service
await consumer.run({
eachMessage: async ({ message }) => {
const { orderId, userId } = JSON.parse(message.value.toString());
await emailService.sendOrderConfirmation(userId, orderId);
}
});
Choosing Between Synchronous and Async
| Criteria | Synchronous | Asynchronous |
|---|---|---|
| Does the caller need an immediate response? | Yes | No |
| Can the operation be deferred? | No | Yes |
| Is the downstream service always available? | Yes | Not required |
| Do you need strong consistency? | Yes | Eventual is OK |
Decomposition Strategies
How to Split a Monolith
- Identify bounded contexts — Use Domain-Driven Design (DDD) to find natural boundaries.
- Start with the highest-value service — Extract a service that has clear independent value.
- Extract one service at a time — Do not attempt a big-bang migration.
- Use the Strangler Fig pattern — Gradually route traffic from monolith to new service.
// Strangler Fig pattern
const gateway = express();
// Route to new service if available, fall back to monolith
gateway.use('/api/users', async (req, res, next) => {
try {
const response = await fetch('http://user-service/api/users' + req.path);
return res.json(await response.json());
} catch {
next(); // Fall through to monolith handler
}
});
Service Granularity Guidelines
| Service Size | Team Size | Deployment Frequency | Example |
|---|---|---|---|
| ⚡ Small | 1-3 developers | Multiple times/day | User verification |
| 📐 Medium | 3-6 developers | Daily/weekly | Order processing |
| 🏗️ Large | 6-10 developers | Weekly | Payment platform |
Rule of thumb: A service should be small enough that a single team can own it entirely, large enough to provide meaningful business value.
Operational Challenges
Observability
Microservices generate massive amounts of telemetry. Three pillars:
1. Logging:
// Structured logging (JSON)
{
"timestamp": "2026-05-24T10:30:00.123Z",
"level": "error",
"service": "payment-service",
"trace_id": "abc123",
"message": "Payment processing failed",
"error": "stripe: insufficient funds",
"metadata": { "order_id": "ord_456", "amount": 2999 }
}
2. Metrics (Prometheus format):
# HELP http_requests_total Total HTTP requests
# TYPE http_requests_total counter
http_requests_total{method="POST",path="/api/payments",status="500"} 42
3. Distributed Tracing (OpenTelemetry):
# OpenTelemetry auto-instrumentation
OTEL_EXPORTER_OTLP_ENDPOINT: "http://otel-collector:4318"
OTEL_SERVICE_NAME: "payment-service"
OTEL_TRACES_SAMPLER: "parentbased_traceidratio"
OTEL_TRACES_SAMPLER_ARG: "0.1"
Service Discovery
In dynamic environments (Kubernetes), IP addresses change. Services find each other via DNS:
- Kubernetes DNS —
payment-service.namespace.svc.cluster.local. - Consul — Service registry with health checks.
- Eureka — Netflix's service discovery (Spring Cloud).
API Gateway
A single entry point for all client requests:
| Function | Example |
|---|---|
| Routing | /api/users → user-service, /api/orders → order-service |
| Authentication | Validate JWT tokens before routing |
| Rate limiting | 1000 req/min per client |
| Request transformation | Convert JSON to Protobuf |
| Response caching | Cache GET responses |
| Circuit breaking | Stop routing to unhealthy services |
Configuration Management
Externalize all configuration:
# ConfigMap in Kubernetes
apiVersion: v1
kind: ConfigMap
metadata:
name: payment-service-config
data:
DATABASE_URL: "postgresql://..."
STRIPE_API_KEY: "${STRIPE_API_KEY}" # from Secret
MAX_RETRIES: "3"
FEATURE_FLAG_NEW_CHECKOUT: "true"
Container Orchestration with Kubernetes
apiVersion: apps/v1
kind: Deployment
metadata:
name: payment-service
spec:
replicas: 3
selector:
matchLabels:
app: payment-service
template:
metadata:
labels:
app: payment-service
spec:
containers:
- name: payment-service
image: registry.example.com/payment-service:latest
ports:
- containerPort: 8080
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
When NOT to Use Microservices
- Small teams (< 10 developers) — Cognitive overhead of microservices outweighs benefits.
- Simple applications — CRUD app with few features. A monolith is faster to build.
- Early-stage startups — Speed of iteration matters more than scalability.
- Unclear domain boundaries — If you cannot identify service boundaries, you will create distributed monolith.
- Low traffic applications — Microservices overhead (networking, deployment, monitoring) is not justified.
Conway's Law: Organizations design systems that mirror their communication structure. If your team is not organized around service boundaries, microservices will create friction.
Migration Strategy
Phase 1: Prepare
- Add monitoring and centralized logging to the monolith.
- Identify bounded contexts using DDD workshops.
- Extract shared libraries (auth, logging, utilities).
- Set up CI/CD and containerization.
Phase 2: Extract
- Extract the first service (lowest risk, highest value).
- Implement the Strangler Fig pattern.
- Run monolith + new service in parallel.
- Add circuit breakers and fallbacks.
Phase 3: Scale
- Extract additional services iteratively.
- Implement event-driven communication where appropriate.
- Add service mesh (Istio, Linkerd) for advanced networking.
- Invest in platform engineering (backstage, developer portals).
Technology Stack Recommendations
| Category | Options | Notes |
|---|---|---|
| Framework | Spring Boot, NestJS, FastAPI, Go kit | Choose based on team expertise |
| API | REST, gRPC, GraphQL | gRPC for internal, REST for external |
| Messaging | Kafka, RabbitMQ, NATS | Kafka for high throughput |
| Database | PostgreSQL, DynamoDB, MongoDB | Match database to service needs |
| Container | Docker | Universal |
| Orchestration | Kubernetes | EKS, AKS, GKE, or self-managed |
| API Gateway | Kong, Envoy, AWS API Gateway | Envoy for service mesh integration |
| Observability | OpenTelemetry, Prometheus, Jaeger | OpenTelemetry is the standard |
| CI/CD | GitHub Actions, GitLab CI, ArgoCD | ArgoCD for GitOps |
| Service Mesh | Istio, Linkerd, Cilium | Linkerd for simplicity |
| Secret Management | HashiCorp Vault, AWS Secrets Manager | Vault for multi-cloud |
Conclusion
Microservices are a powerful architectural pattern that enables independent deployment, team autonomy, and scalable systems. However, they come with significant operational complexity. The most successful microservices adoptions:
- Start with a monolith — Understand your domain before splitting.
- Extract services incrementally — One service at a time.
- Invest heavily in automation — CI/CD, monitoring, and infrastructure as code.
- Organize teams around services — Align team structure with architecture.
- Embrace eventual consistency — Not everything needs to be strongly consistent.
Microservices are not the default architecture — they are a solution to specific scaling and organizational problems. Choose them deliberately, not by default.
Comments
0 commentsNo approved comments are visible yet. New community replies may wait for moderation.