Article
In-Memory Databases and Caching: Speed at Scale
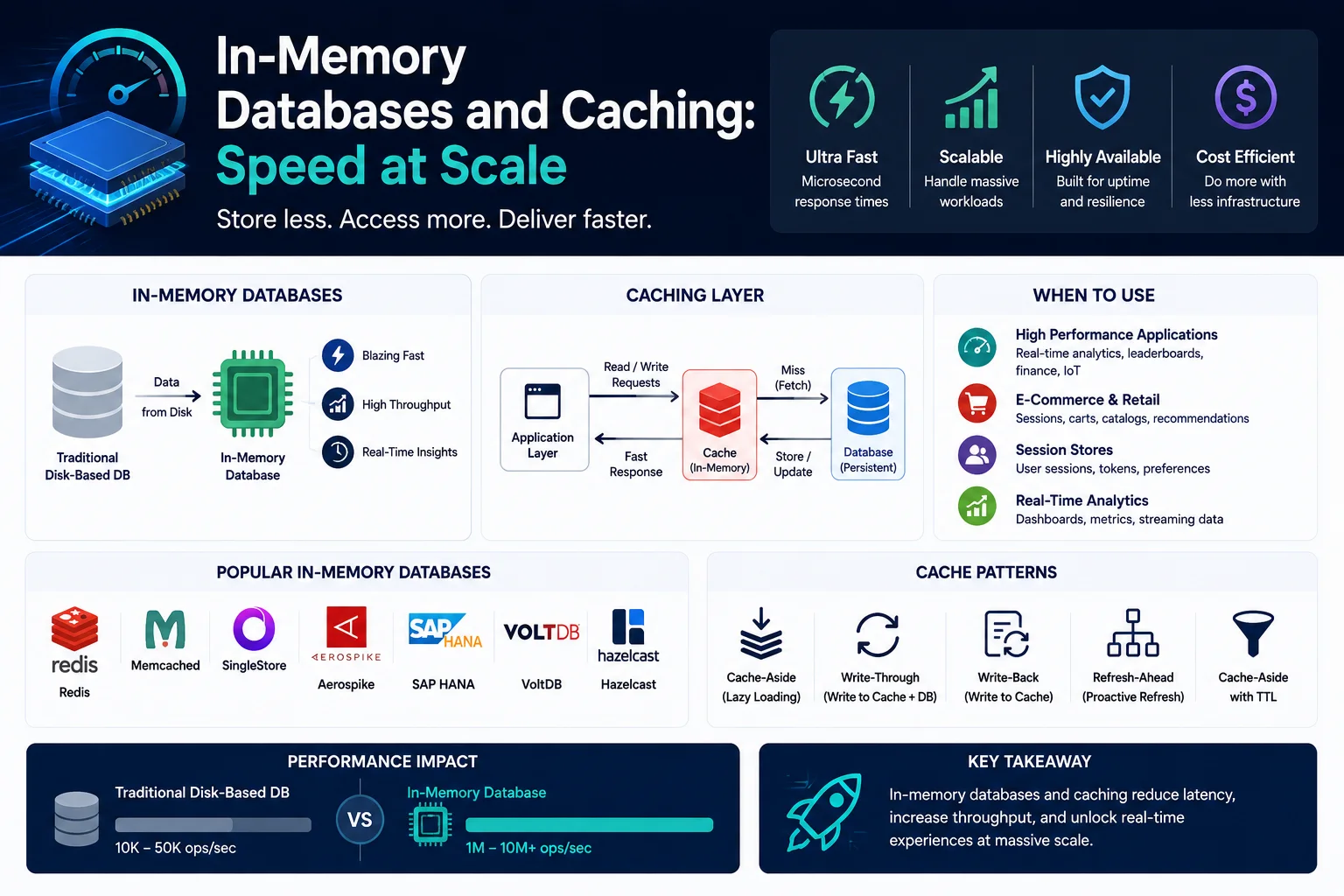
In-memory databases store data primarily in RAM rather than on disk. This eliminates disk I/O latency, providing microsecond response times — orders of magnitude faster than traditional disk-based databases.
3 min readLanguage: EN EnglishFree0 claps0 comments
TechnologyEngineering ArticlesCachingDatabasesTechnologyEngineering ArticlesMemory
Reading options
Introduction
In-memory databases store data primarily in RAM rather than on disk. This eliminates disk I/O latency, providing microsecond response times — orders of magnitude faster than traditional disk-based databases.
In-memory databases are not replacements for traditional databases — they are complementary. They excel at use cases requiring ultra-low latency, high throughput, and real-time data processing: caching, session management, real-time analytics, leaderboards, rate limiting, and message brokering.
In-Memory vs. Disk-Based Databases
| Aspect | In-Memory Database | Disk-Based Database |
|---|---|---|
| Primary storage | RAM | SSD / HDD |
| Read latency | < 1ms (typical 0.1ms) | 1-10ms (SSD), 5-20ms (HDD) |
| Write throughput | 100K-1M+ ops/sec | 1K-100K ops/sec |
| Data persistence | Optional (snapshots, AOF) | Always persistent |
| Capacity | RAM-limited (GBs-TBs) | Disk-limited (TBs-PBs) |
| Cost per GB | ~$10-50/GB | ~$0.10-1/GB |
| Query complexity | Key-value, simple structures | Complex joins, aggregations |
| Durability | Configurable (fsync trade-off) | Full ACID guarantees |
Redis: The Most Popular In-Memory Store
Data Structures
# Strings — most basic
SET user:100:name "Alice"
GET user:100:name # "Alice"
INCR page_counter # 1
INCRBY page_counter 5 # 6
# Lists — ordered, push/pop from ends
LPUSH notifications:101 "New message"
RPOP notifications:101 # "New message"
LLEN notifications:101 # Length
# Sets — unordered, unique members
SADD user:100:tags "redis" "python" "database"
SMEMBERS user:100:tags # All members
SISMEMBER user:100:tags "python" # 1 (true)
SINTER user:100:tags user:200:tags # Intersection
# Sorted Sets — scored, ordered
ZADD leaderboard 1000 "player1"
ZADD leaderboard 2500 "player2" 900 "player3"
ZREVRANGE leaderboard 0 2 WITHSCORES # Top 3
# 1) "player2" (2500)
# 2) "player3" (900)
# 3) "player1" (1000)
# Hashes — structured objects
HSET user:100 name "Alice" age 30 email "alice@example.com"
HGETALL user:100
HINCRBY user:100 login_count 1
# Streams — append-only log (like Kafka)
XADD events * type "login" user_id "100"
XRANGE events - + COUNT 10
# Geospatial — location-based
GEOADD locations 13.361389 38.115556 "Palermo"
GEORADIUS locations 15 37 100 km # Cities within 100km
Persistence Options
| Mode | How It Works | Durability | Performance Impact |
|---|---|---|---|
| RDB (snapshot) | Periodic full dump to disk | Last dump lost | Low (fork + write) |
| AOF (append-only) | Every write logged | Configurable: always/sec/no | Medium |
| RDB + AOF | Both combined | High | Medium |
| No persistence | RAM only, no disk I/O | None on restart | Best performance |
# redis.conf — persistence configuration
save 900 1 # RDB: save if 1 key changed in 900 seconds
save 300 10 # save if 10 keys changed in 300 seconds
save 60 10000 # save if 10000 keys changed in 60 seconds
appendonly yes # Enable AOF
appendfsync everysec # fsync every second (best trade-off)
Production Redis Architecture
Master-Replica:
Client ──► Master (read/write)
│
┌────┴────┐
│ │
Replica1 Replica2 (read-only, failover targets)
Redis Sentinel — High Availability:
┌──────────┐
│ Sentinel │ (monitors master, performs automatic failover)
└──────────┘
│
Client ──► Master ──► Replica1 ──► Replica2
│
(if master fails, Sentinel promotes a replica)
Redis Cluster — Sharding:
Client ──► Any node (auto-redirect to correct shard)
Shard 1 (Master A + Replica A')
Shard 2 (Master B + Replica B')
Shard 3 (Master C + Replica C')
Hash slots: 0-16383 distributed across shards
No central proxy — clients connect directly
Caching Patterns
Cache-Aside (lazy loading):
def get_user(user_id: str) -> dict:
# Try cache first
cached = redis.get(f"user:{user_id}")
if cached:
return json.loads(cached)
# Cache miss — load from database
user = db.query("SELECT * FROM users WHERE id = %s", user_id)
# Store in cache with TTL
redis.setex(f"user:{user_id}", 3600, json.dumps(user))
return user
Write-Through:
def update_user(user_id: str, data: dict):
# Update database
db.execute("UPDATE users SET ... WHERE id = %s", data, user_id)
# Update cache immediately
redis.setex(f"user:{user_id}", 3600, json.dumps(data))
Write-Behind (async):
def write_behind(user_id: str, data: dict):
# First to cache (instant)
redis.setex(f"user:{user_id}", 3600, json.dumps(data))
# Queue for async database write
redis.lpush("write_queue", json.dumps({
'user_id': user_id,
'data': data,
'timestamp': time.time()
}))
# Background worker processes the queue
def write_worker():
while True:
task = json.loads(redis.brpop("write_queue")[1])
db.execute("UPDATE users SET ... WHERE id = %s",
task['data'], task['user_id'])
Caching Strategies
Cache Invalidation Strategies
| Strategy | Mechanism | Best For |
|---|---|---|
| TTL-based | Set time-to-live, auto-expire | Stale data acceptable |
| Write-through | Update cache on every write | Read-heavy, write-light |
| Write-behind | Async write to DB | Write-heavy, eventual consistency OK |
| Cache invalidation | Explicit delete/update | Strong consistency needed |
| Version-based | Cache key includes version | Schema changes |
Eviction Policies
| Policy | Description | Use Case |
|---|---|---|
| LRU (Least Recently Used) | Evict oldest accessed key | General purpose |
| LFU (Least Frequently Used) | Evict least accessed key | Stable access patterns |
| TTL | Auto-expire keys | Session data, temporary cache |
| Random | Random eviction | Simple, predictable |
| No eviction | Return error on full memory | Critical data must stay |
# Redis eviction policy
maxmemory 4gb
maxmemory-policy allkeys-lru # or: volatile-lru, allkeys-lfu, volatile-ttl
Other In-Memory Databases
Memcached — Simple, Fast, Multi-Threaded
# Simple key-value (no persistence, no replication)
memcached -m 4096 -p 11211 -t 4
# Usage (similar to Redis but simpler)
set user:100 0 3600 15 # key, flags, ttl, byte_count
"Hello, World!"
get user:100
Redis vs. Memcached:
| Feature | Redis | Memcached |
|---|---|---|
| Data structures | Strings, lists, sets, hashes, streams, etc. | Strings only |
| Persistence | RDB + AOF | None |
| Replication | Master-replica + Cluster | None |
| Transactions | MULTI/EXEC, Lua | None |
| Memory efficiency | Good (has compression options) | Better (lower overhead) |
| Threading | Single-threaded (event loop) | Multi-threaded |
| Use case | General purpose cache + data structures | Simple cache only |
Dragonfly — Modern Redis Alternative
# Dragonfly is multi-threaded (faster on multi-core CPUs)
dragonfly --bind 0.0.0.0 --port 6379
# Same Redis protocol, same clients
redis-cli SET key value
redis-cli GET key
Hazelcast, Apache Ignite — Distributed In-Memory Data Grids
// Hazelcast — distributed cache with processing
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.map.IMap;
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IMap<String, User> cache = hz.getMap("users");
cache.put("user:100", user);
User cached = cache.get("user:100");
// Distributed computing
cache.executeOnKey("user:100", entry -> {
User user = entry.getValue();
user.incrementLoginCount();
entry.setValue(user);
return null;
});
Common Use Cases
1. Session Stores
def create_session(user_id: str) -> str:
session_id = str(uuid.uuid4())
redis.setex(
f"session:{session_id}",
86400 * 7, # 7 days
json.dumps({
'user_id': user_id,
'created_at': time.time(),
'ip': request.remote_addr,
'user_agent': request.user_agent,
})
)
return session_id
def validate_session(session_id: str) -> dict | None:
data = redis.get(f"session:{session_id}")
if data:
return json.loads(data)
return None
2. Rate Limiting
import time
def check_rate_limit(user_id: str, max_requests: int = 100,
window_seconds: int = 60) -> bool:
key = f"ratelimit:{user_id}:{int(time.time()) // window_seconds}"
count = redis.incr(key)
if count == 1:
redis.expire(key, window_seconds)
return count <= max_requests
# Token bucket algorithm (more precise)
def token_bucket(user_id: str, capacity: int = 100,
refill_rate: float = 1.0) -> bool:
key = f"token_bucket:{user_id}"
now = time.time()
lua = """
local key = KEYS[1]
local now = tonumber(ARGV[1])
local capacity = tonumber(ARGV[2])
local refill_rate = tonumber(ARGV[3])
local bucket = redis.call('HMGET', key, 'tokens', 'last_refill')
local tokens = tonumber(bucket[1]) or capacity
local last_refill = tonumber(bucket[2]) or now
local elapsed = now - last_refill
tokens = math.min(capacity, tokens + elapsed * refill_rate)
if tokens >= 1 then
tokens = tokens - 1
redis.call('HMSET', key, 'tokens', tokens, 'last_refill', now)
return 1
else
return 0
end
"""
return bool(redis.eval(lua, 1, key, now, capacity, refill_rate))
3. Real-Time Leaderboards
def add_score(game_id: str, player: str, score: int):
redis.zadd(f"leaderboard:{game_id}", {player: score})
def get_top_players(game_id: str, n: int = 10) -> list[dict]:
results = redis.zrevrange(
f"leaderboard:{game_id}", 0, n - 1,
withscores=True
)
return [
{"player": player.decode(), "score": int(score)}
for player, score in results
]
def get_player_rank(game_id: str, player: str) -> int:
rank = redis.zrevrank(f"leaderboard:{game_id}", player)
return rank + 1 if rank is not None else None
4. Message Queue / Pub-Sub
# PUBLISH/SUBSCRIBE
# Publisher
redis.publish("notifications:global",
json.dumps({"type": "alert", "message": "System update at 2AM"}))
# Subscriber (separate process)
pubsub = redis.pubsub()
pubsub.subscribe("notifications:global")
for message in pubsub.listen():
if message['type'] == 'message':
process_notification(json.loads(message['data']))
# List-based queue (reliable)
redis.lpush("task_queue", json.dumps(task))
task = redis.brpop("task_queue") # Blocking pop
Performance Optimization
Serialization Impact
| Format | Serialization | Deserialization | Size (1000 items) |
|---|---|---|---|
| Pickle (Python) | 1x | 1x | 100KB |
| JSON | 0.8x | 0.7x | 180KB |
| MessagePack | 0.6x | 0.5x | 130KB |
| Protobuf | 0.9x | 0.4x | 75KB |
| Custom binary | 0.3x | 0.2x | 55KB |
Pipeline (Reduce Round-Trips)
# Without pipeline: N round-trips
for user_id in user_ids:
redis.get(f"user:{user_id}") # N network calls
# With pipeline: 1 round-trip
pipe = redis.pipeline()
for user_id in user_ids:
pipe.get(f"user:{user_id}")
results = pipe.execute() # Single network call
Connection Pooling
import redis
class RedisPool:
_instance = None
_pool = None
@classmethod
def get_connection(cls) -> redis.Redis:
if cls._pool is None:
cls._pool = redis.ConnectionPool(
host='redis-cluster.example.com',
port=6379,
max_connections=100,
socket_timeout=2,
retry_on_timeout=True,
health_check_interval=30,
)
return redis.Redis(connection_pool=cls._pool)
Monitoring
# Redis INFO
redis-cli INFO
# Key metrics to monitor:
connected_clients: 42
used_memory_human: 3.2G
used_memory_peak_human: 4.1G
total_commands_processed: 15238912
keyspace_hits: 984532
keyspace_misses: 5214
expired_keys: 11245
evicted_keys: 0
instantaneous_ops_per_sec: 4532
| Metric | Warning | Critical | Action |
|---|---|---|---|
| Memory usage | > 80% of maxmemory | > 95% | Scale up, optimize TTL |
| Hit rate | < 85% | < 70% | Review caching strategy |
| Replication lag | > 1 second | > 10 seconds | Check network, replica |
| Evicted keys | > 0 | > 100/hour | Increase memory or TTL |
Conclusion
In-memory databases are essential infrastructure for modern, high-performance applications:
- Use for caching — Reduce database load, improve response times.
- Use for real-time data — Leaderboards, rate limiting, session management.
- Use as a message broker — Pub/sub, task queues, event streams.
- Redis is the default choice — Rich data structures, persistence options, clustering.
- Never use as primary database — Data loss risk, memory limitations, limited query capability.
Decision Framework
Need sub-millisecond latency?
├─ Yes
│ Q: Complexity of operations?
│ ├─ Simple key-value: Memcached
│ ├─ Data structures, persistence: Redis
│ └─ Distributed computing: Hazelcast/Ignite
└─ No
Q: Data fits in memory?
├─ Yes: Consider in-memory for performance
└─ No: Disk-based (PostgreSQL, etc.)
In-memory databases are not about replacing databases — they are about making everything faster.
Comments
0 commentsNo approved comments are visible yet. New community replies may wait for moderation.