Article
Graph Databases: Modeling Connected Data
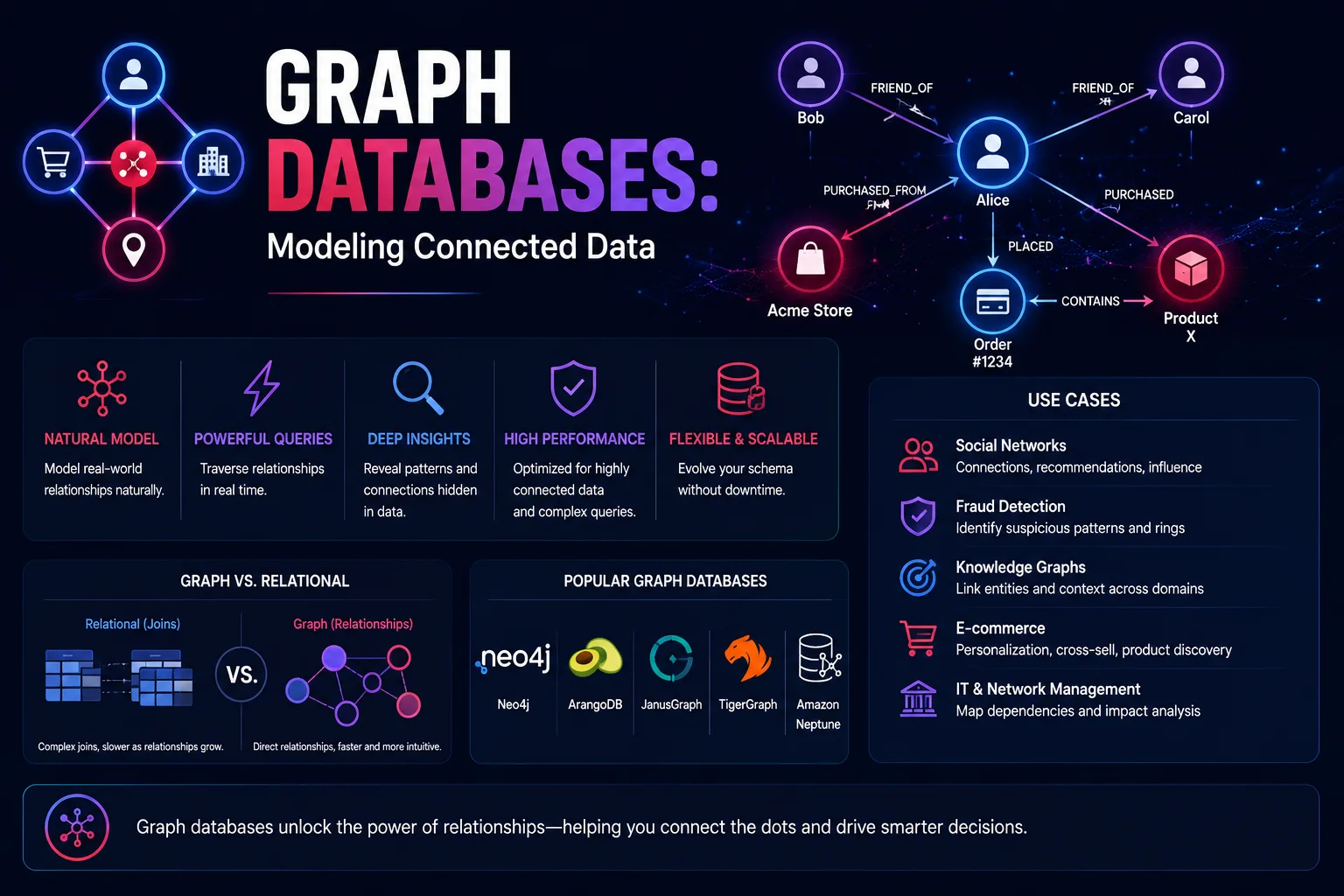
Graph databases are purpose-built for storing and querying highly connected data. While relational databases excel at tabular data with known relationships, graph databases excel when relationships are as important as the data itself — social networks, recommendation engines, fraud detection, knowledge graphs, and supply chains.
4 min readLanguage: EN EnglishFree0 claps0 comments
TechnologyEngineering ArticlesDatabasesTechnologyEngineering ArticlesGraphModeling
Reading options
Introduction
Graph databases are purpose-built for storing and querying highly connected data. While relational databases excel at tabular data with known relationships, graph databases excel when relationships are as important as the data itself — social networks, recommendation engines, fraud detection, knowledge graphs, and supply chains.
The fundamental insight: in many domains, the connections between entities ARE the data, and graph databases make those connections a first-class citizen.
Graph Database Concepts
Property Graph Model
┌──────────────────┐
│ Person │
│ name: "Alice" │
│ age: 30 │
└────────┬─────────┘
│
┌────────▼─────────┐
│ KNOWS │
│ since: 2020 │
│ type: "friend" │
└────────┬─────────┘
│
┌────────▼─────────┐
│ Person │
│ name: "Bob" │
│ age: 32 │
└──────────────────┘
Three core components:
| Component | Description | Example |
|---|---|---|
| Node (Vertex) | An entity in the graph | Person, Company, Product |
| Edge (Relationship) | A connection between two nodes | KNOWS, WORKS_AT, PURCHASED |
| Property | Attributes on nodes or edges | name: "Alice", since: 2020 |
Relational vs. Graph
Querying relationships in SQL:
-- Find friends of friends who work at Google
SELECT DISTINCT p3.name
FROM persons p1
JOIN friendships f1 ON p1.id = f1.person_id
JOIN persons p2 ON f1.friend_id = p2.id
JOIN friendships f2 ON p2.id = f2.person_id
JOIN persons p3 ON f2.friend_id = p3.id
JOIN employment e ON p3.id = e.person_id
JOIN companies c ON e.company_id = c.id
WHERE p1.name = 'Alice'
AND c.name = 'Google';
Same query in Cypher (Neo4j):
MATCH (alice:Person {name: "Alice"})
-[:KNOWS*2]->
(friend_of_friend:Person)
MATCH (friend_of_friend)-[:WORKS_AT]->(google:Company {name: "Google"})
RETURN DISTINCT friend_of_friend.name
Key difference: SQL juggles multiple JOINs. Graph traversals match patterns naturally.
Graph Query Languages
Cypher (Neo4j) — Declarative Pattern Matching
// Create nodes and relationships
CREATE (alice:Person {name: "Alice", age: 30})
CREATE (bob:Person {name: "Bob", age: 32})
CREATE (alice)-[:KNOWS {since: 2020}]->(bob)
// Find friends of friends who bought products in the last month
MATCH (user:Person {id: $userId})
-[:KNOWS]->
(friend:Person)
-[:PURCHASED]->
(product:Product)
WHERE product.purchased_at > datetime() - duration('P1M')
RETURN product.name, count(*) as purchase_count
ORDER BY purchase_count DESC
LIMIT 10
// Shortest path between two people
MATCH p = shortestPath(
(alice:Person {name: "Alice"})-[:KNOWS*]-(bob:Person {name: "Bob"})
)
RETURN length(p) as degrees_of_separation,
[node IN nodes(p) | node.name] as path
Gremlin (Apache TinkerPop) — Imperative Graph Traversal
// Same query in Gremlin
g.V().has('Person', 'name', 'Alice')
.repeat(out('KNOWS')).times(2)
.out('WORKS_AT')
.has('Company', 'name', 'Google')
.values('name')
.dedup()
SPARQL (RDF) — Semantic Web
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX org: <http://www.w3.org/ns/org#>
SELECT ?name WHERE {
?alice foaf:name "Alice" ;
foaf:knows ?friend .
?friend foaf:knows ?friend_of_friend .
?friend_of_friend org:memberOf ?company .
?company org:legalName "Google" .
?friend_of_friend foaf:name ?name .
}
Graph Database Comparison
| Feature | Neo4j | Amazon Neptune | ArangoDB | JanusGraph | Dgraph |
|---|---|---|---|---|---|
| Query language | Cypher | Gremlin/SPARQL | AQL | Gremlin | GraphQL+ |
| Storage | Native graph | RDF/Property | Multi-model | Cassandra/HBase | Badger |
| Clustering | Enterprise | Managed | Yes | Yes | Yes |
| ACID | Yes | Yes | Yes | Per-storage | Yes |
| Free tier | Community (1 node) | Pay-as-you-go | Open-source | Open-source | Open-source |
| Best for | Enterprise graphs | AWS ecosystem | Multi-model | Big data graphs | High performance |
| Vector search | ✅ (5.x+) | ❌ | ✅ | ❌ | ❌ |
Use Cases
1. Social Networks and Recommendations
(User:Alice)-[:KNOWS]->(User:Bob)
(User:Alice)-[:LIKES]->(Movie:Inception)
(User:Bob)-[:LIKES]->(Movie:Inception)
(User:Charlie)-[:KNOWS]->(User:Alice)
Recommendation query — "Movies liked by friends of friends":
MATCH (me:User {id: $userId})
-[:KNOWS*1..2]-
(other:User)
-[:LIKES]->
(movie:Movie)
WHERE NOT EXISTS {
(me)-[:LIKES]->(movie)
OR (me)-[:DISLIKES]->(movie)
}
RETURN movie.title, count(DISTINCT other) as friend_count,
avg(other.rating) as avg_rating
ORDER BY friend_count DESC, avg_rating DESC
LIMIT 20
2. Fraud Detection
Fraud rings exhibit complex, non-obvious patterns. Graph queries detect them efficiently:
// Detect potential fraud rings:
// Multiple accounts sharing same device, IP, or phone
MATCH (account:Account)
-[:USED_DEVICE]->(device:Device)<-[:USED_DEVICE]-
(other:Account),
(account)-[:USED_IP]->(ip:IPAddress)<-[:USED_IP]-
(other)
WHERE account.id <> other.id
AND account.created_at > datetime() - duration('P7D')
RETURN account.id, other.id, device.device_id, ip.address,
count(*) as connection_count
ORDER BY connection_count DESC
LIMIT 100
Fraud detection statistics:
| Metric | Before Graph | After Graph |
|---|---|---|
| Detection rate | 65% | 93% |
| False positive rate | 8% | 2% |
| Investigation time per case | 45 min | 5 min |
3. Knowledge Graphs
Knowledge graphs connect structured and unstructured data into a unified web of meaning:
// Create a knowledge graph from documents
LOAD CSV WITH HEADERS FROM 'file:///entities.csv' AS row
CREATE (e:Entity {
id: row.id,
name: row.name,
type: row.type,
description: row.description
});
LOAD CSV WITH HEADERS FROM 'file:///relationships.csv' AS row
MATCH (a:Entity {id: row.source_id})
MATCH (b:Entity {id: row.target_id})
CALL apoc.create.relationship(a, row.relationship_type, {
source_document: row.document,
confidence: toFloat(row.confidence)
}) YIELD rel
RETURN count(*);
// Query: "How does Product X relate to Regulation Y?"
MATCH path = shortestPath(
(product:Entity {name: "Product X"})
-[:AFFECTS|REGULATES|DEPENDS_ON|MANUFACTURED_BY*]-
(regulation:Entity {name: "Regulation Y"})
)
RETURN [node IN nodes(path) | {name: node.name, type: node.type}],
[rel IN relationships(path) | type(rel)]
4. Supply Chain
// Find all suppliers that feed into a critical component
MATCH (component:Part {name: "Critical Microchip"})
<-[:PRODUCES]-
(:Factory)
-[:SOURCES_FROM]->
(supplier:Supplier)
-[:SUPPLIED_BY]->
(sub_supplier:Supplier)
WHERE sub_supplier.location IN ["Region_A", "Region_B"]
RETURN component.name, supplier.name, sub_supplier.name,
sub_supplier.location
// Impact analysis: "If Supplier X fails, which products are affected?"
MATCH (failing:Supplier {id: $supplierId})
<-[:SUPPLIED_BY]-*
(factory:Factory)
-[:PRODUCES]->
(product:Product)
RETURN product.name, product.revenue,
count(DISTINCT factory) as factories_affected
ORDER BY product.revenue DESC
Graph Database Internals
Index-Free Adjacency
The fundamental performance advantage of native graph databases: each node directly points to its connected neighbors. No index lookups needed for traversals.
Relational Database: Graph Database:
┌────────┐
Find friends: │ Alice │──┐
1. Index lookup on person_id ──┐ │ │ │
2. Index lookup on friend_id ──┤ └────────┘ │
3. Join results ──┤ │ │
4. Fetch friend data ──┤ ┌──▼─────┐ │
│ │ Bob │◄─┘
O(log N) per hop │ │ │
│ └────────┘
│
For 6 degrees of separation: │ O(1) per traversal hop
O(log N × 6) = O(log N) │ O(6) = O(1)
│
│ For 6 hops: 6 pointer dereferences
Graph Partitioning
For distributed graph databases, partitioning is challenging:
| Strategy | Description | Problem |
|---|---|---|
| Edge-cut | Split by vertex, edges cross partitions | Many cross-partition traversals |
| Vertex-cut | Split by edge, vertex replicated | Consistency overhead |
| Hash partitioning | Hash vertices to partitions | Random — poor locality |
| Range partitioning | Partition by property value | Skew if data is not uniform |
Advanced Graph Patterns
Temporal Graphs (Time-Travel Queries)
// Property graph with versioned edges
MATCH (employee:Employee {id: $empId})
-[assignment:ASSIGNED_TO]->(project:Project)
WHERE assignment.from_date <= date("2026-01-15")
AND (assignment.to_date IS NULL OR assignment.to_date >= date("2026-01-15"))
RETURN employee.name, project.name, assignment.role
// What was the org structure on Jan 1, 2025?
MATCH (manager:Employee)
-[reports:MANAGES]->(report:Employee)
WHERE reports.effective_from <= date("2025-01-01")
AND (reports.effective_to IS NULL OR reports.effective_to > date("2025-01-01"))
RETURN manager.name, collect(report.name) as reports
Graph Algorithms (Neo4j GDS)
from neo4j import GraphDatabase
from graphdatascience import GraphDataScience
gds = GraphDataScience("bolt://localhost:7687", auth=("neo4j", "password"))
# Create in-memory graph
G, result = gds.graph.project(
"myGraph",
["Person", "Company"],
["KNOWS", "WORKS_AT"]
)
# PageRank — find influential people
pagerank = gds.pageRank.stream(G)
influencers = pagerank.sort_values('score', ascending=False).head(10)
# Community detection (Louvain) — find clusters
communities = gds.louvain.stream(G)
Graph + Vector Search (Hybrid)
Modern graph databases (Neo4j 5.x+) support both graph and vector search:
// Find similar products using vector embeddings,
// then traverse the recommendation graph
CALL db.index.vector.queryNodes(
'product-embeddings',
10,
$query_embedding
) YIELD node AS similar_product, score
MATCH (similar_product)-[:ALSO_BOUGHT]->(recommended:Product)
WHERE recommended.rating > 4.0
RETURN recommended.name, recommended.price, score
ORDER BY score DESC, recommended.rating DESC
LIMIT 20
Graph Database Anti-Patterns
| Anti-Pattern | Why It Hurts | Better Approach |
|---|---|---|
| Global operations | MATCH (n) WHERE n.property scans all nodes |
Add index: CREATE INDEX FOR (n:Label) ON (n.property) |
| Deep unlimited traversals | MATCH (a)-[*]->(b) without limit |
Specify depth: [*1..5] |
| Supernodes | One node with millions of edges | Break into intermediate nodes, use time-boundaries |
| Missing direction | Bidirectional edges cause double traversal | Define clear direction and traverse efficiently |
| Over-normalization | Creating nodes for simple attributes | Use node properties instead |
When to Use a Graph Database
Use Graph When:
- Relationships are first-class — the connections ARE the data.
- Traversal depth is variable — 2-hop vs. 6-hop queries change dynamically.
- Schema evolves frequently — adding new relationship types on the fly.
- Pattern matching is the query pattern — "find paths that look like X."
- Complex join chains — 5+ JOINs in SQL suggest a graph might be better.
Don't Use Graph When:
- Data is purely tabular — sales records, transaction logs.
- Aggregate-heavy workloads — "total revenue by region" (SQL/column store is better).
- Simple CRUD by ID — "find user by email" (relational DB is fine).
- High-volume point queries — millions of simple lookups per second.
Conclusion
Graph databases excel where relationships are complex, variable, and central to the domain. They are not a replacement for relational databases — they are a complementary tool for specific problem spaces.
- Social and recommendation systems — traverse friend-of-friend graphs naturally.
- Fraud detection — find non-obvious connections in financial networks.
- Knowledge graphs — connect data from diverse sources into a unified model.
- Supply chain and logistics — model complex multi-tier relationships.
- Network and IT operations — dependency graphs, root cause analysis.
Best practice: Start with Neo4j (most mature ecosystem), use Cypher for queries, and combine with vector search for AI-powered graph applications. Keep traversal depths bounded, index labeled properties, and monitor supernode growth.
Comments
0 commentsNo approved comments are visible yet. New community replies may wait for moderation.