Artikel
Microservices-Architektur
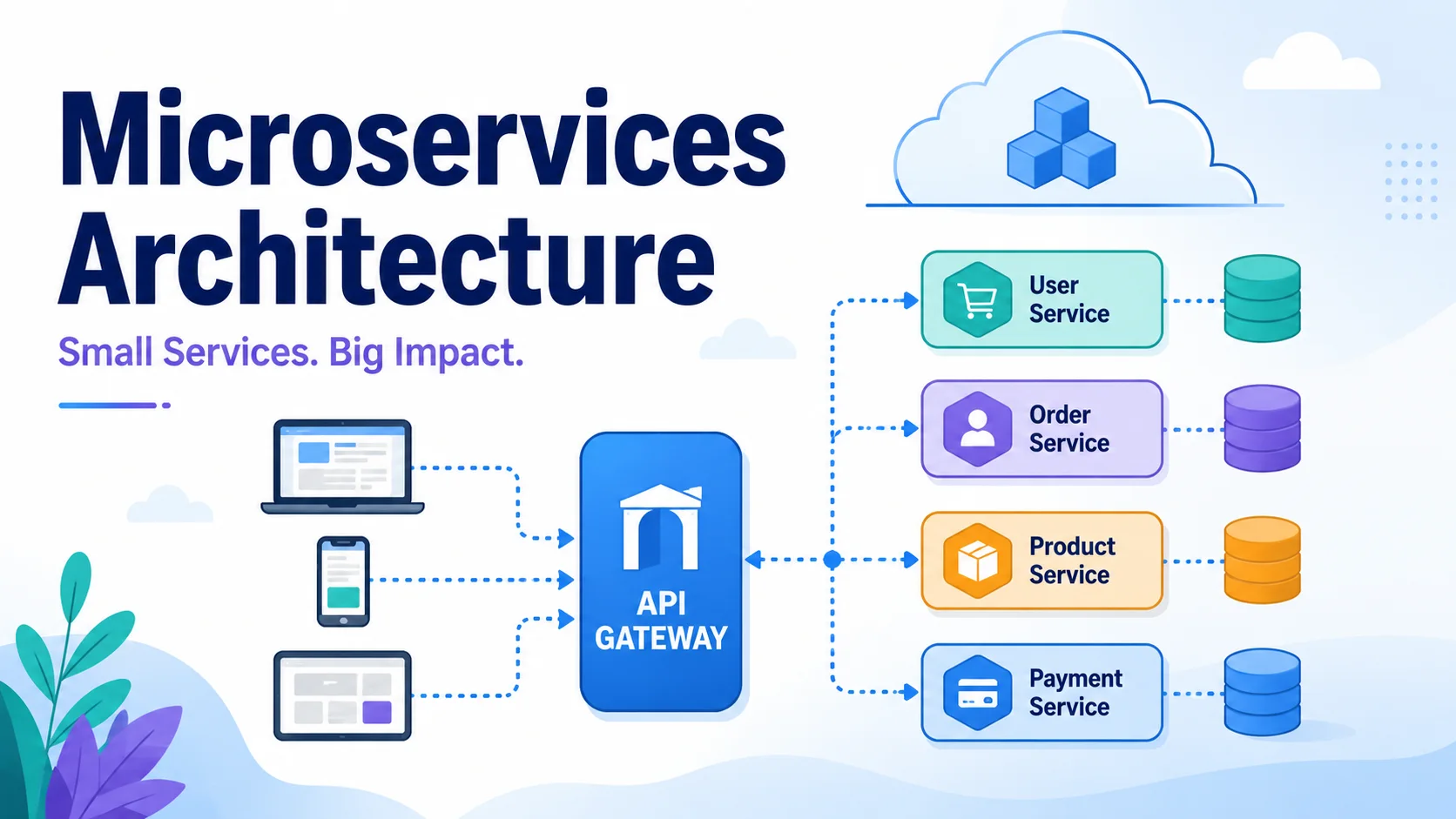
Die Microservices-Architektur strukturiert eine Anwendung als eine Sammlung lose gekoppelter, unabhängig voneinander bereitstellbarer Dienste. Jeder Dienst verfügt über eine bestimmte Geschäftsfunktion, verfügt über einen eigenen Datenspeicher und kommuniziert über ein Netzwerk. Obwohl Microservices eine erhebliche betriebliche Komplexität mit sich bringen, ermöglichen sie Unternehmen die Skalierung von Entwicklungsteams, die unabhängige Bereitstellung und den Aufbau widerstandsfähigerer Systeme.
5 Min. LesezeitSprache: DE DeutschKostenlos0 Claps0 Kommentare
TechnologieEngineering-ArtikelDevOpsArchitectureMicroservicesTechnologyEngineering Articles
Leseoptionen
Einführung
Die Microservices-Architektur strukturiert eine Anwendung als eine Sammlung lose gekoppelter, unabhängig voneinander bereitstellbarer Dienste. Jeder Dienst verfügt über eine bestimmte Geschäftsfunktion, verfügt über einen eigenen Datenspeicher und kommuniziert über ein Netzwerk. Obwohl Microservices eine erhebliche betriebliche Komplexität mit sich bringen, ermöglichen sie Unternehmen die Skalierung von Entwicklungsteams, die unabhängige Bereitstellung und den Aufbau widerstandsfähigerer Systeme.
Monolith vs. Microservices
Der Monolith
Eine monolithische Anwendung verfügt über alle Funktionen in einer einzigen Codebasis und Bereitstellungseinheit:
┌─────────────────────────────────────────────┐
│ Monolith Application │
├──────────────┬──────────────┬───────────────┤
│ User Module │ Order Module│ Payment │
│ (controllers, services, repos, DB tables) │
└──────────────┴──────────────┴───────────────┘
Monolith-Vorteile:
- Einfache Entwicklung und Tests (einzelner Prozess).
- Einfaches Debuggen (keine Netzwerkaufrufe zwischen Modulen).
- Schnelle Kommunikation (In-Memory-Methodenaufrufe).
- Keine verteilte Systemkomplexität.
- Ideal für kleine Teams und Produkte im Frühstadium.
Nachteile des Monolithen:
- Skalierung bedeutet, alles zu skalieren, nicht nur den Engpass.
- Ein einzelner Fehler kann die gesamte Anwendung zum Absturz bringen.
- Der Technologie-Stack ist gesperrt.
- Eine große Codebasis wird schwer zu verstehen und zu warten.
- Die Bereitstellung dauert länger, wenn die Codebasis wächst.
- Der Aufwand für die Teamkoordination steigt.
Die Microservices-Architektur
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ User Service │ │ Order Service │ │ Payment Service │
│ (own DB, API) │ │ (own DB, API) │ │ (own DB, API) │
└────────┬─────────┘ └────────┬─────────┘ └────────┬─────────┘
│ │ │
└──────────────────────┼──────────────────────┘
│
┌───────────▼───────────┐
│ API Gateway │
│ (auth, routing) │
└───────────────────────┘
Grundprinzipien
1. Einzelverantwortung
Jeder Dienst besitzt genau eine Geschäftsfähigkeit. Wenn Sie den Zweck eines Dienstes beschreiben können, ohne „und“ zu verwenden, ist er wahrscheinlich gut abgegrenzt.
Gut:
- „Payment-Service“ – kümmert sich um die Zahlungsabwicklung und Rückerstattungen.
- „notification-service“ – Sendet E-Mails, SMS und Push-Benachrichtigungen.
- „inventory-service“ – Verwaltet Lagerbestände und Reservierungen.
Schlecht:
- „Benutzer-und-Bestelldienst“ – Zwei unterschiedliche Funktionen kombiniert (verstößt gegen SRP).
- „Backend-Service“ – Alles in einem Service (überhaupt keine Microservices).
2. Dezentrales Datenmanagement
Jeder Dienst besitzt seine Datenbank. Dienste teilen niemals Datenbanken – sie kommunizieren über APIs.
-- Service A has its own database
CREATE TABLE users (
id UUID PRIMARY KEY,
email VARCHAR(255) UNIQUE,
name VARCHAR(255)
);
-- Service B has its own database, stores only the user ID
CREATE TABLE orders (
id UUID PRIMARY KEY,
user_id UUID NOT NULL,
total DECIMAL(10,2),
status VARCHAR(50)
);
Warum nicht Datenbanken teilen?
- Enge Kopplung – Schemaänderungen in einem Dienst unterbrechen andere.
- Unterschiedliche Dienste haben unterschiedliche Speicheranforderungen (relational vs. Dokument vs. Diagramm).
- Ein eigenständiger Einsatz wird unmöglich.
- Die Skalierung erfordert koordinierte Schemamigrationen.
3. Belastbarkeit und Fehlerisolierung
Ein Ausfall in einem Dienst sollte nicht auf andere übergreifen.
Leistungsschaltermuster:
// Using a circuit breaker to handle service failures gracefully
const breaker = new CircuitBreaker({
failureThreshold: 5,
resetTimeout: 30000, // 30 seconds
});
async function getPaymentStatus(orderId: string) {
try {
return await breaker.call(() => paymentService.getStatus(orderId));
} catch (error) {
// Fallback: return cached status or default
return { status: 'pending', note: 'Payment service unavailable' };
}
}
Schottmuster: Weisen Sie verschiedenen Diensten separate Thread-Pools zu, damit ein langsamer Dienst nicht alle Ressourcen erschöpft:
// Separate thread pools per service
const paymentPool = new ThreadPool({ maxThreads: 10 });
const inventoryPool = new ThreadPool({ maxThreads: 20 });
const notificationPool = new ThreadPool({ maxThreads: 5 });
4. Unabhängige Einsatzfähigkeit
Jeder Dienst kann unabhängig bereitgestellt werden. Dies ist der Hauptvorteil von Microservices.
Bereitstellungsautomatisierung:
# GitHub Actions for a single microservice
name: Deploy Payment Service
on:
push:
paths:
- 'services/payment/**'
- '.github/workflows/payment.yml'
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: docker build -t payment-service .
- run: docker push registry.example.com/payment-service:${{ github.sha }}
- run: kubectl set image deployment/payment-service payment-service=registry.example.com/payment-service:${{ github.sha }}
Kommunikationsmuster
Synchrone Kommunikation (REST, gRPC)
Vorteile: Einfach zu implementieren und zu überdenken. Die Semantik von Anfragen und Antworten ist bekannt.
Nachteile: Erstellt Laufzeitkopplung – wenn der Downstream-Dienst ausfällt, ist der Aufrufer betroffen.
// REST call using fetch
const order = await fetch(`http://order-service:8080/api/orders/${orderId}`);
// gRPC definition
service OrderService {
rpc GetOrder (GetOrderRequest) returns (Order);
}
message GetOrderRequest {
string order_id = 1;
}
Asynchrone Kommunikation (Nachrichtenwarteschlangen)
Vorteile: Lose Kopplung, bessere Ausfallsicherheit, unterstützt ereignisgesteuerte Architekturen.
Nachteile: Eventualkonsistenz, schwieriger zu debuggen, erfordert Nachrichteninfrastruktur.
// Kafka producer
await producer.send({
topic: 'order.created',
messages: [{ value: JSON.stringify({ orderId, userId, total }) }]
});
// Kafka consumer in notification service
await consumer.run({
eachMessage: async ({ message }) => {
const { orderId, userId } = JSON.parse(message.value.toString());
await emailService.sendOrderConfirmation(userId, orderId);
}
});
Wählen Sie zwischen synchron und asynchron
| Kriterien | Synchron | Asynchron |
|---|---|---|
| Benötigt der Anrufer eine sofortige Antwort? | Ja | NEIN |
| Kann die Operation verschoben werden? | NEIN | Ja |
| Ist der Downstream-Dienst immer verfügbar? | Ja | Nicht erforderlich |
| Benötigen Sie eine starke Konsistenz? | Ja | Letztendlich ist es in Ordnung |
Zersetzungsstrategien
So teilen Sie einen Monolithen
- Begrenzte Kontexte identifizieren – Verwenden Sie Domain-Driven Design (DDD), um natürliche Grenzen zu finden.
- Beginnen Sie mit dem Dienst mit dem höchsten Wert – Extrahieren Sie einen Dienst, der einen klaren unabhängigen Wert hat.
- Extrahieren Sie jeweils einen Dienst – Versuchen Sie keine Big-Bang-Migration.
- Verwenden Sie das Strangler Fig-Muster – Leiten Sie den Verkehr schrittweise vom Monolithen zum neuen Dienst weiter.
// Strangler Fig pattern
const gateway = express();
// Route to new service if available, fall back to monolith
gateway.use('/api/users', async (req, res, next) => {
try {
const response = await fetch('http://user-service/api/users' + req.path);
return res.json(await response.json());
} catch {
next(); // Fall through to monolith handler
}
});
Richtlinien zur Servicegranularität
| Servicegröße | Teamgröße | Bereitstellungshäufigkeit | Beispiel |
|---|---|---|---|
| ⚡ Klein | 1-3 Entwickler | Mehrmals/Tag | Benutzerüberprüfung |
| 📐 Mittel | 3-6 Entwickler | Täglich/wöchentlich | Auftragsabwicklung |
| 🏗️ Groß | 6-10 Entwickler | Wöchentlich | Zahlungsplattform |
Faustregel: Ein Service sollte klein genug sein, dass ein einzelnes Team ihn vollständig besitzen kann, und groß genug, um einen sinnvollen Geschäftswert zu bieten.
Operative Herausforderungen
Beobachtbarkeit
Microservices erzeugen riesige Mengen an Telemetrie. Drei Säulen:
1. Protokollierung:
// Structured logging (JSON)
{
"timestamp": "2026-05-24T10:30:00.123Z",
"level": "error",
"service": "payment-service",
"trace_id": "abc123",
"message": "Payment processing failed",
"error": "stripe: insufficient funds",
"metadata": { "order_id": "ord_456", "amount": 2999 }
}
2. Metriken (Prometheus-Format):
# HELP http_requests_total Total HTTP requests
# TYPE http_requests_total counter
http_requests_total{method="POST",path="/api/payments",status="500"} 42
3. Verteiltes Tracing (OpenTelemetry):
# OpenTelemetry auto-instrumentation
OTEL_EXPORTER_OTLP_ENDPOINT: "http://otel-collector:4318"
OTEL_SERVICE_NAME: "payment-service"
OTEL_TRACES_SAMPLER: "parentbased_traceidratio"
OTEL_TRACES_SAMPLER_ARG: "0.1"
Diensterkennung
In dynamischen Umgebungen (Kubernetes) ändern sich IP-Adressen. Dienste finden sich über DNS:
- Kubernetes DNS – „ payment-service.namespace.svc.cluster.local“.
- Consul – Dienstregister mit Gesundheitschecks.
- Eureka – Netflix-Diensterkennung (Spring Cloud).
API-Gateway
Ein einziger Einstiegspunkt für alle Kundenanfragen:
| Funktion | Beispiel |
|---|---|
| Routenführung | /api/users → Benutzerdienst, /api/orders → Bestellservice |
| Authentifizierung | Validieren Sie JWT-Tokens vor dem Routing |
| Ratenbegrenzung | 1000 Anforderungen/Minute pro Kunde |
| Fordern Sie eine Transformation an | Konvertieren Sie JSON in Protobuf |
| Antwort-Caching | GET-Antworten zwischenspeichern |
| Stromkreisunterbrechung | Stoppen Sie die Weiterleitung an fehlerhafte Dienste |
Konfigurationsmanagement
Alle Konfigurationen externalisieren:
# ConfigMap in Kubernetes
apiVersion: v1
kind: ConfigMap
metadata:
name: payment-service-config
data:
DATABASE_URL: "postgresql://..."
STRIPE_API_KEY: "${STRIPE_API_KEY}" # from Secret
MAX_RETRIES: "3"
FEATURE_FLAG_NEW_CHECKOUT: "true"
Container-Orchestrierung mit Kubernetes
apiVersion: apps/v1
kind: Deployment
metadata:
name: payment-service
spec:
replicas: 3
selector:
matchLabels:
app: payment-service
template:
metadata:
labels:
app: payment-service
spec:
containers:
- name: payment-service
image: registry.example.com/payment-service:latest
ports:
- containerPort: 8080
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
Wann Sie Microservices NICHT verwenden sollten
- Kleine Teams (< 10 Entwickler) – Der kognitive Aufwand von Microservices überwiegt die Vorteile.
- Einfache Anwendungen – CRUD-App mit wenigen Funktionen. Ein Monolith ist schneller zu bauen.
- Startups im Frühstadium – Iterationsgeschwindigkeit ist wichtiger als Skalierbarkeit.
- Unklare Domänengrenzen – Wenn Sie Servicegrenzen nicht identifizieren können, erstellen Sie einen verteilten Monolithen.
- Anwendungen mit geringem Datenverkehr – Der Mehraufwand für Microservices (Netzwerk, Bereitstellung, Überwachung) ist nicht gerechtfertigt.
Conways Gesetz: Organisationen entwerfen Systeme, die ihre Kommunikationsstruktur widerspiegeln. Wenn Ihr Team nicht entlang der Servicegrenzen organisiert ist, werden Microservices zu Reibungsverlusten führen.
Migrationsstrategie
Phase 1: Vorbereiten
- Fügen Sie dem Monolithen Überwachung und zentrale Protokollierung hinzu.
- Identifizieren Sie begrenzte Kontexte mithilfe von DDD-Workshops.
- Extrahieren Sie gemeinsam genutzte Bibliotheken (Authentifizierung, Protokollierung, Dienstprogramme).
- CI/CD und Containerisierung einrichten.
Phase 2: Extrahieren
- Extrahieren Sie den ersten Dienst (geringstes Risiko, höchster Wert).
- Implementieren Sie das Strangler Fig-Muster.
- Führen Sie Monolith + neuen Dienst parallel aus.
- Fügen Sie Leistungsschalter und Fallbacks hinzu.
Phase 3: Skalierung
- Extrahieren Sie zusätzliche Dienste iterativ.
- Implementieren Sie gegebenenfalls ereignisgesteuerte Kommunikation.
- Fügen Sie Service Mesh (Istio, Linkerd) für erweiterte Netzwerke hinzu.
- Investieren Sie in Plattform-Engineering (Backstage, Entwicklerportale).
Empfehlungen zum Technologie-Stack
| Kategorie | Optionen | Notizen |
|---|---|---|
| Rahmen | Spring Boot, NestJS, FastAPI, Go-Kit | Wählen Sie basierend auf der Teamkompetenz |
| API | REST, gRPC, GraphQL | gRPC für intern, REST für extern |
| Nachrichten | Kafka, RabbitMQ, NATS | Kafka für hohen Durchsatz |
| Datenbank | PostgreSQL, DynamoDB, MongoDB | Passen Sie die Datenbank an die Serviceanforderungen an |
| Container | Docker | Universal |
| Orchestrierung | Kubernetes | EKS, AKS, GKE oder selbstverwaltet |
| API-Gateway | Kong, Envoy, AWS API Gateway | Gesandter für Service-Mesh-Integration |
| Beobachtbarkeit | OpenTelemetry, Prometheus, Jaeger | OpenTelemetry ist der Standard |
| CI/CD | GitHub-Aktionen, GitLab CI, ArgoCD | ArgoCD für GitOps |
| Service-Mesh | Istio, Linkerd, Cilium | Der Einfachheit halber verlinkt |
| Geheimes Management | HashiCorp Vault, AWS Secrets Manager | Tresor für Multi-Cloud |
Abschluss
Microservices sind ein leistungsstarkes Architekturmuster, das unabhängige Bereitstellung, Teamautonomie und skalierbare Systeme ermöglicht. Allerdings sind sie mit einer erheblichen betrieblichen Komplexität verbunden. Die erfolgreichsten Microservices-Einführungen:
- Beginnen Sie mit einem Monolithen – Machen Sie sich mit Ihrer Domain vertraut, bevor Sie sie aufteilen.
- Dienste schrittweise extrahieren – jeweils ein Dienst.
- Investieren Sie stark in Automatisierung – CI/CD, Überwachung und Infrastruktur als Code.
- Organisieren Sie Teams rund um Services – Richten Sie die Teamstruktur an der Architektur aus.
- Empfehlen Sie eventuelle Konsistenz – Nicht alles muss streng konsistent sein.
Microservices sind nicht die Standardarchitektur – sie sind eine Lösung für spezifische Skalierungs- und Organisationsprobleme. Wählen Sie sie bewusst und nicht standardmäßig aus.
Kommentare
0 KommentareNoch keine freigegebenen Kommentare sichtbar. Neue Antworten können moderiert werden.