Artikel
In-Memory-Datenbanken und Caching: Geschwindigkeit im Maßstab
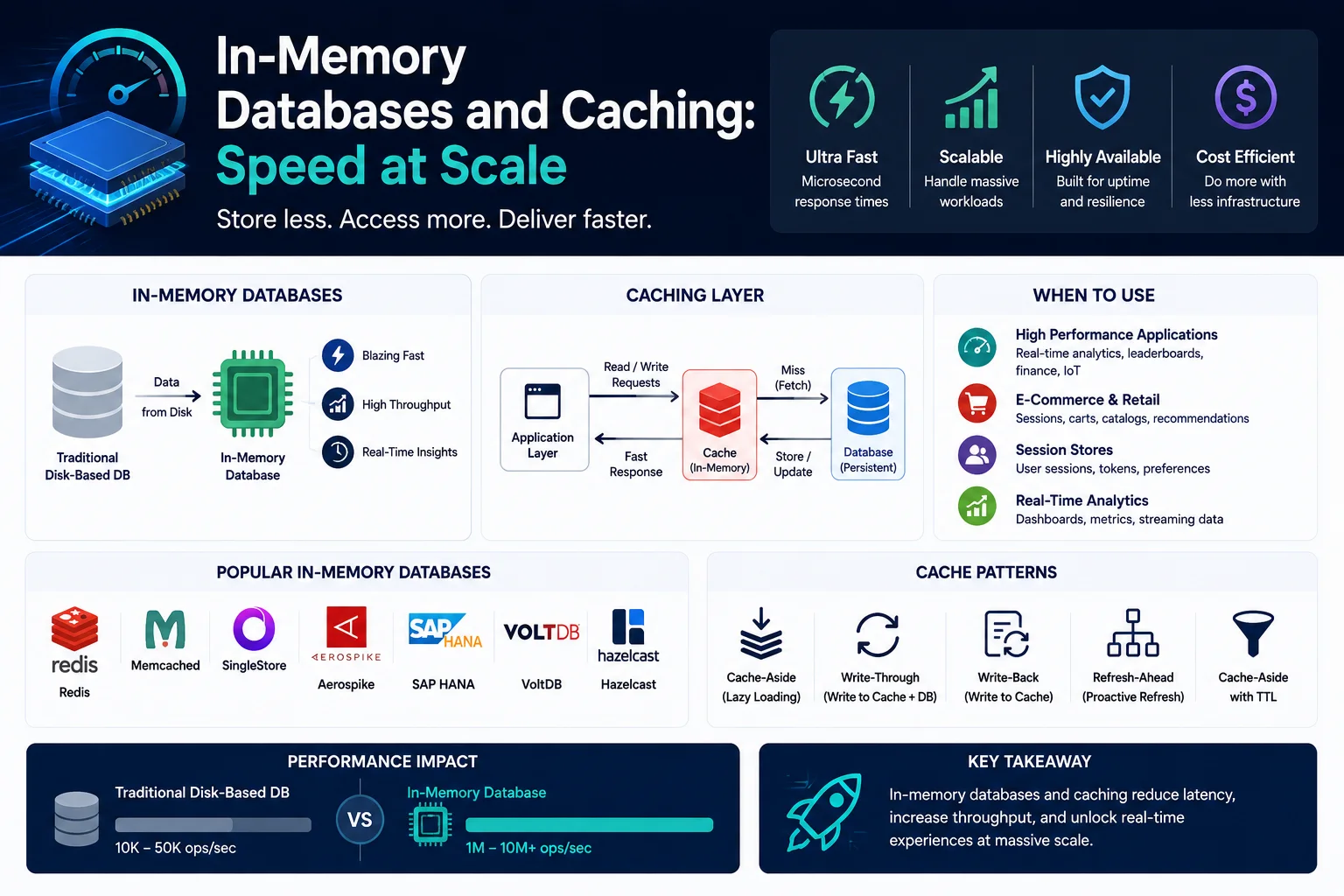
In-Memory-Datenbanken speichern Daten hauptsächlich im RAM und nicht auf der Festplatte. Dadurch entfällt die I/O-Latenz der Festplatte und es werden Reaktionszeiten im Mikrosekundenbereich erreicht – um Größenordnungen schneller als bei herkömmlichen festplattenbasierten Datenbanken.
3 Min. LesezeitSprache: DE DeutschKostenlos0 Claps0 Kommentare
TechnologieEngineering-ArtikelCachingDatabasesTechnologyEngineering ArticlesMemory
Leseoptionen
Einführung
In-Memory-Datenbanken speichern Daten hauptsächlich im RAM und nicht auf der Festplatte. Dadurch entfällt die I/O-Latenz der Festplatte und es werden Reaktionszeiten im Mikrosekundenbereich erreicht – um Größenordnungen schneller als bei herkömmlichen festplattenbasierten Datenbanken.
In-Memory-Datenbanken sind kein Ersatz für herkömmliche Datenbanken – sie ergänzen diese. Sie zeichnen sich durch Anwendungsfälle aus, die extrem niedrige Latenz, hohen Durchsatz und Echtzeit-Datenverarbeitung erfordern: Caching, Sitzungsverwaltung, Echtzeitanalysen, Bestenlisten, Ratenbegrenzung und Nachrichtenvermittlung.
In-Memory vs. festplattenbasierte Datenbanken
| Aspekt | In-Memory-Datenbank | Festplattenbasierte Datenbank |
|---|---|---|
| Primärspeicher | RAM | SSD/HDD |
| Leselatenz | < 1 ms (typisch 0,1 ms) | 1–10 ms (SSD), 5–20 ms (HDD) |
| Schreibdurchsatz | 100.000–1 Mio.+ Vorgänge/Sek | 1.000–100.000 Vorgänge/Sek |
| Datenpersistenz | Optional (Schnappschüsse, AOF) | Immer hartnäckig |
| Kapazität | RAM-begrenzt (GBs-TBs) | Festplattenbegrenzt (TBs-PBs) |
| Kosten pro GB | ~10–50 $/GB | ~0,10–1 $/GB |
| Abfragekomplexität | Schlüsselwerte, einfache Strukturen | Komplexe Verknüpfungen, Aggregationen |
| Haltbarkeit | Konfigurierbar (Fsync-Kompromiss) | Volle ACID-Garantie |
Redis: Der beliebteste In-Memory-Store
Datenstrukturen
# Strings — most basic
SET user:100:name "Alice"
GET user:100:name # "Alice"
INCR page_counter # 1
INCRBY page_counter 5 # 6
# Lists — ordered, push/pop from ends
LPUSH notifications:101 "New message"
RPOP notifications:101 # "New message"
LLEN notifications:101 # Length
# Sets — unordered, unique members
SADD user:100:tags "redis" "python" "database"
SMEMBERS user:100:tags # All members
SISMEMBER user:100:tags "python" # 1 (true)
SINTER user:100:tags user:200:tags # Intersection
# Sorted Sets — scored, ordered
ZADD leaderboard 1000 "player1"
ZADD leaderboard 2500 "player2" 900 "player3"
ZREVRANGE leaderboard 0 2 WITHSCORES # Top 3
# 1) "player2" (2500)
# 2) "player3" (900)
# 3) "player1" (1000)
# Hashes — structured objects
HSET user:100 name "Alice" age 30 email "alice@example.com"
HGETALL user:100
HINCRBY user:100 login_count 1
# Streams — append-only log (like Kafka)
XADD events * type "login" user_id "100"
XRANGE events - + COUNT 10
# Geospatial — location-based
GEOADD locations 13.361389 38.115556 "Palermo"
GEORADIUS locations 15 37 100 km # Cities within 100km
Persistenzoptionen
| Modus | Wie es funktioniert | Haltbarkeit | Auswirkungen auf die Leistung |
|---|---|---|---|
| RDB (Schnappschuss) | Periodischer vollständiger Speicherauszug auf die Festplatte | Letzter Dump verloren | Niedrig (Gabel + Schreiben) |
| AOF (nur anhängen) | Jeder Schreibvorgang wird protokolliert | Konfigurierbar: immer/sek/nr | Mittel |
| RDB + AOF | Beides kombiniert | Hoch | Mittel |
| Keine Persistenz | Nur RAM, keine Festplatten-E/A | Keine beim Neustart | Beste Leistung |
# redis.conf — persistence configuration
save 900 1 # RDB: save if 1 key changed in 900 seconds
save 300 10 # save if 10 keys changed in 300 seconds
save 60 10000 # save if 10000 keys changed in 60 seconds
appendonly yes # Enable AOF
appendfsync everysec # fsync every second (best trade-off)
Produktions-Redis-Architektur
Master-Replikat:
Client ──► Master (read/write)
│
┌────┴────┐
│ │
Replica1 Replica2 (read-only, failover targets)
Redis Sentinel – Hohe Verfügbarkeit:
┌──────────┐
│ Sentinel │ (monitors master, performs automatic failover)
└──────────┘
│
Client ──► Master ──► Replica1 ──► Replica2
│
(if master fails, Sentinel promotes a replica)
Redis-Cluster – Sharding:
Client ──► Any node (auto-redirect to correct shard)
Shard 1 (Master A + Replica A')
Shard 2 (Master B + Replica B')
Shard 3 (Master C + Replica C')
Hash slots: 0-16383 distributed across shards
No central proxy — clients connect directly
Caching-Muster
Cache-Aside (verzögertes Laden):
def get_user(user_id: str) -> dict:
# Try cache first
cached = redis.get(f"user:{user_id}")
if cached:
return json.loads(cached)
# Cache miss — load from database
user = db.query("SELECT * FROM users WHERE id = %s", user_id)
# Store in cache with TTL
redis.setex(f"user:{user_id}", 3600, json.dumps(user))
return user
Durchschreiben:
def update_user(user_id: str, data: dict):
# Update database
db.execute("UPDATE users SET ... WHERE id = %s", data, user_id)
# Update cache immediately
redis.setex(f"user:{user_id}", 3600, json.dumps(data))
Write-Behind (asynchron):
def write_behind(user_id: str, data: dict):
# First to cache (instant)
redis.setex(f"user:{user_id}", 3600, json.dumps(data))
# Queue for async database write
redis.lpush("write_queue", json.dumps({
'user_id': user_id,
'data': data,
'timestamp': time.time()
}))
# Background worker processes the queue
def write_worker():
while True:
task = json.loads(redis.brpop("write_queue")[1])
db.execute("UPDATE users SET ... WHERE id = %s",
task['data'], task['user_id'])
Caching-Strategien
Strategien zur Cache-Invalidierung
| Strategie | Mechanismus | Am besten für |
|---|---|---|
| TTL-basiert | Legen Sie die Gültigkeitsdauer und den automatischen Ablauf fest | Veraltete Daten akzeptabel |
| Durchschreiben | Cache bei jedem Schreibvorgang aktualisieren | Lesestark, schreibleicht |
| Write-behind | Asynchrones Schreiben in die Datenbank | Schreiblastig, letztendliche Konsistenz OK |
| Cache-Ungültigmachung | Explizites Löschen/Aktualisieren | Starke Konsistenz erforderlich |
| Versionsbasiert | Der Cache-Schlüssel enthält die Version | Schemaänderungen |
Räumungsrichtlinien
| Politik | Beschreibung | Anwendungsfall |
|---|---|---|
| LRU (Am wenigsten kürzlich verwendet) | Ältesten Zugriffsschlüssel entfernen | Allgemeiner Zweck |
| LFU (am seltensten verwendet) | Schlüssel mit dem geringsten Zugriff entfernen | Stabile Zugriffsmuster |
| TTL | Schlüssel mit automatischem Ablauf | Sitzungsdaten, temporärer Cache |
| Zufällig | Zufällige Räumung | Einfach, vorhersehbar |
| Keine Räumung | Rückgabefehler bei vollem Speicher | Kritische Daten müssen bleiben |
# Redis eviction policy
maxmemory 4gb
maxmemory-policy allkeys-lru # or: volatile-lru, allkeys-lfu, volatile-ttl
Andere In-Memory-Datenbanken
Memcached – Einfach, schnell, Multi-Threaded
# Simple key-value (no persistence, no replication)
memcached -m 4096 -p 11211 -t 4
# Usage (similar to Redis but simpler)
set user:100 0 3600 15 # key, flags, ttl, byte_count
"Hello, World!"
get user:100
Redis vs. Memcached:
| Funktion | Redis | Im Speicher gespeichert |
|---|---|---|
| Datenstrukturen | Strings, Listen, Sets, Hashes, Streams usw. | Nur Saiten |
| Beharrlichkeit | RDB + AOF | Keine |
| Replikation | Master-Replikat + Cluster | Keine |
| Transaktionen | MULTI/EXEC, Lua | Keine |
| Speichereffizienz | Gut (hat Komprimierungsoptionen) | Besser (geringerer Overhead) |
| Einfädeln | Single-Threaded (Ereignisschleife) | Multithreaded |
| Anwendungsfall | Allzweck-Cache + Datenstrukturen | Nur einfacher Cache |
Dragonfly – Moderne Redis-Alternative
# Dragonfly is multi-threaded (faster on multi-core CPUs)
dragonfly --bind 0.0.0.0 --port 6379
# Same Redis protocol, same clients
redis-cli SET key value
redis-cli GET key
Hazelcast, Apache Ignite – Verteilte In-Memory-Datengrids
// Hazelcast — distributed cache with processing
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.map.IMap;
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IMap<String, User> cache = hz.getMap("users");
cache.put("user:100", user);
User cached = cache.get("user:100");
// Distributed computing
cache.executeOnKey("user:100", entry -> {
User user = entry.getValue();
user.incrementLoginCount();
entry.setValue(user);
return null;
});
Häufige Anwendungsfälle
1. Sitzungsspeicher
def create_session(user_id: str) -> str:
session_id = str(uuid.uuid4())
redis.setex(
f"session:{session_id}",
86400 * 7, # 7 days
json.dumps({
'user_id': user_id,
'created_at': time.time(),
'ip': request.remote_addr,
'user_agent': request.user_agent,
})
)
return session_id
def validate_session(session_id: str) -> dict | None:
data = redis.get(f"session:{session_id}")
if data:
return json.loads(data)
return None
2. Ratenbegrenzung
import time
def check_rate_limit(user_id: str, max_requests: int = 100,
window_seconds: int = 60) -> bool:
key = f"ratelimit:{user_id}:{int(time.time()) // window_seconds}"
count = redis.incr(key)
if count == 1:
redis.expire(key, window_seconds)
return count <= max_requests
# Token bucket algorithm (more precise)
def token_bucket(user_id: str, capacity: int = 100,
refill_rate: float = 1.0) -> bool:
key = f"token_bucket:{user_id}"
now = time.time()
lua = """
local key = KEYS[1]
local now = tonumber(ARGV[1])
local capacity = tonumber(ARGV[2])
local refill_rate = tonumber(ARGV[3])
local bucket = redis.call('HMGET', key, 'tokens', 'last_refill')
local tokens = tonumber(bucket[1]) or capacity
local last_refill = tonumber(bucket[2]) or now
local elapsed = now - last_refill
tokens = math.min(capacity, tokens + elapsed * refill_rate)
if tokens >= 1 then
tokens = tokens - 1
redis.call('HMSET', key, 'tokens', tokens, 'last_refill', now)
return 1
else
return 0
end
"""
return bool(redis.eval(lua, 1, key, now, capacity, refill_rate))
3. Echtzeit-Bestenlisten
def add_score(game_id: str, player: str, score: int):
redis.zadd(f"leaderboard:{game_id}", {player: score})
def get_top_players(game_id: str, n: int = 10) -> list[dict]:
results = redis.zrevrange(
f"leaderboard:{game_id}", 0, n - 1,
withscores=True
)
return [
{"player": player.decode(), "score": int(score)}
for player, score in results
]
def get_player_rank(game_id: str, player: str) -> int:
rank = redis.zrevrank(f"leaderboard:{game_id}", player)
return rank + 1 if rank is not None else None
4. Nachrichtenwarteschlange / Pub-Sub
# PUBLISH/SUBSCRIBE
# Publisher
redis.publish("notifications:global",
json.dumps({"type": "alert", "message": "System update at 2AM"}))
# Subscriber (separate process)
pubsub = redis.pubsub()
pubsub.subscribe("notifications:global")
for message in pubsub.listen():
if message['type'] == 'message':
process_notification(json.loads(message['data']))
# List-based queue (reliable)
redis.lpush("task_queue", json.dumps(task))
task = redis.brpop("task_queue") # Blocking pop
Leistungsoptimierung
Auswirkungen der Serialisierung
| Formatieren | Serialisierung | Deserialisierung | Größe (1000 Artikel) |
|---|---|---|---|
| Gurke (Python) | 1x | 1x | 100 KB |
| JSON | 0,8x | 0,7x | 180 KB |
| MessagePack | 0,6x | 0,5x | 130 KB |
| Protobuf | 0,9x | 0,4x | 75 KB |
| Benutzerdefinierte Binärdatei | 0,3x | 0,2x | 55 KB |
Pipeline (Round-Trips reduzieren)
# Without pipeline: N round-trips
for user_id in user_ids:
redis.get(f"user:{user_id}") # N network calls
# With pipeline: 1 round-trip
pipe = redis.pipeline()
for user_id in user_ids:
pipe.get(f"user:{user_id}")
results = pipe.execute() # Single network call
Verbindungspooling
import redis
class RedisPool:
_instance = None
_pool = None
@classmethod
def get_connection(cls) -> redis.Redis:
if cls._pool is None:
cls._pool = redis.ConnectionPool(
host='redis-cluster.example.com',
port=6379,
max_connections=100,
socket_timeout=2,
retry_on_timeout=True,
health_check_interval=30,
)
return redis.Redis(connection_pool=cls._pool)
Überwachung
# Redis INFO
redis-cli INFO
# Key metrics to monitor:
connected_clients: 42
used_memory_human: 3.2G
used_memory_peak_human: 4.1G
total_commands_processed: 15238912
keyspace_hits: 984532
keyspace_misses: 5214
expired_keys: 11245
evicted_keys: 0
instantaneous_ops_per_sec: 4532
| Metrisch | Warnung | Kritisch | Aktion |
|---|---|---|---|
| Speichernutzung | > 80 % des maximalen Speichers | > 95 % | Hochskalieren, TTL optimieren |
| Trefferquote | < 85 % | < 70 % | Überprüfen Sie die Caching-Strategie |
| Replikationsverzögerung | > 1 Sekunde | > 10 Sekunden | Netzwerk prüfen, Replikat |
| Schlüssel vertrieben | > 0 | > 100/Stunde | Erhöhen Sie den Speicher oder die TTL |
Fazit
In-Memory-Datenbanken sind eine wesentliche Infrastruktur für moderne, leistungsstarke Anwendungen:
- Zum Caching verwenden – Reduzieren Sie die Datenbanklast und verbessern Sie die Antwortzeiten.
- Verwendung für Echtzeitdaten – Bestenlisten, Ratenbegrenzung, Sitzungsverwaltung.
- Verwendung als Nachrichtenbroker – Pub/Sub, Aufgabenwarteschlangen, Ereignisströme.
- Redis ist die Standardauswahl – Umfangreiche Datenstrukturen, Persistenzoptionen, Clustering.
- Niemals als primäre Datenbank verwenden – Datenverlustrisiko, Speicherbeschränkungen, eingeschränkte Abfragefähigkeit.
Entscheidungsrahmen
Need sub-millisecond latency?
├─ Yes
│ Q: Complexity of operations?
│ ├─ Simple key-value: Memcached
│ ├─ Data structures, persistence: Redis
│ └─ Distributed computing: Hazelcast/Ignite
└─ No
Q: Data fits in memory?
├─ Yes: Consider in-memory for performance
└─ No: Disk-based (PostgreSQL, etc.)
Bei In-Memory-Datenbanken geht es nicht darum, Datenbanken zu ersetzen – es geht darum, alles schneller zu machen.
Kommentare
0 KommentareNoch keine freigegebenen Kommentare sichtbar. Neue Antworten können moderiert werden.