Artikel
Graphdatenbanken: Modellierung verbundener Daten
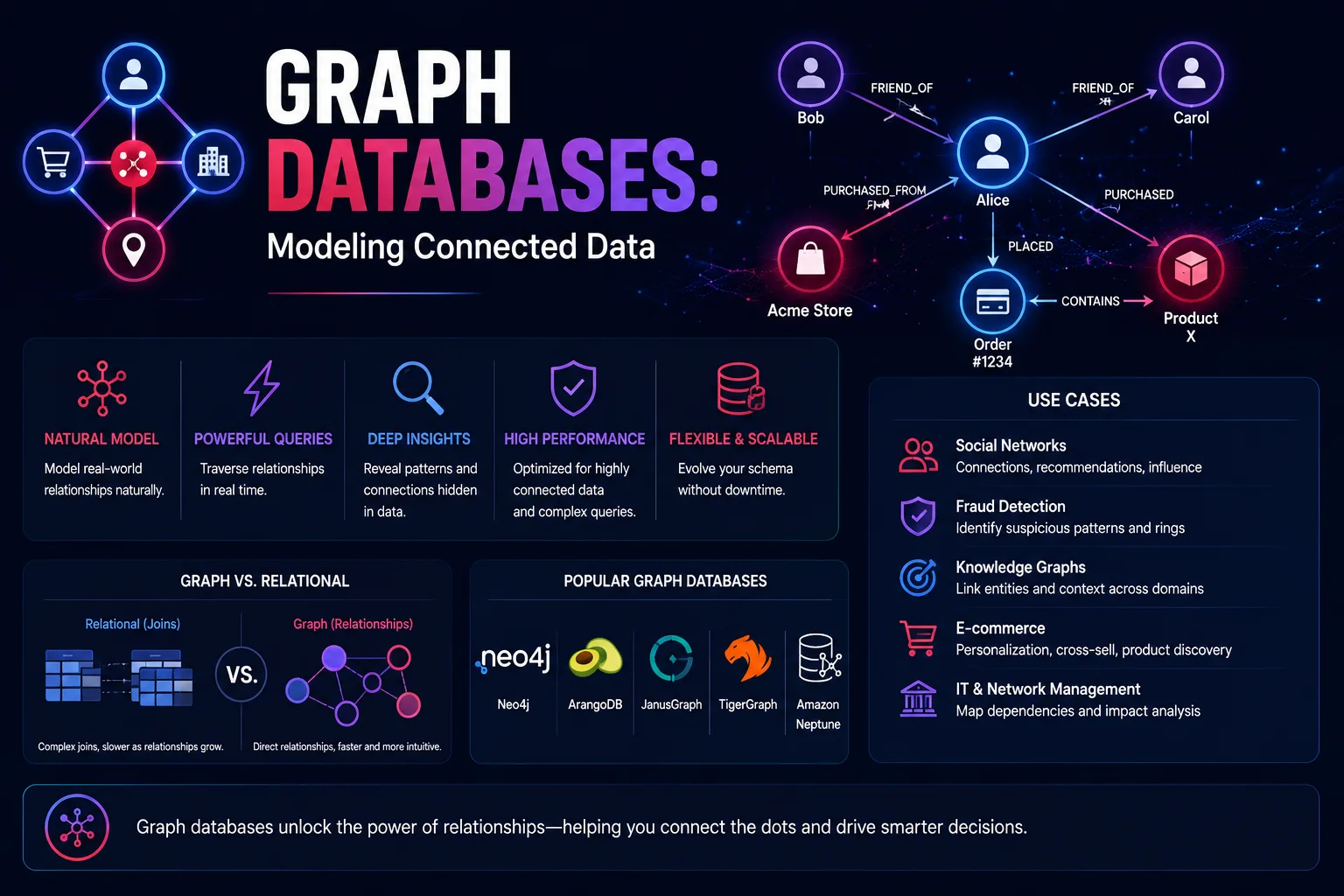
Graphdatenbanken sind speziell für die Speicherung und Abfrage stark vernetzter Daten konzipiert. Während sich relationale Datenbanken bei tabellarischen Daten mit bekannten Beziehungen auszeichnen, zeichnen sich Diagrammdatenbanken aus, wenn Beziehungen genauso wichtig sind wie die Daten selbst – soziale Netzwerke, Empfehlungsmaschinen, Betrugserkennung, Wissensgraphen und Lieferketten.
4 Min. LesezeitSprache: DE DeutschKostenlos0 Claps0 Kommentare
TechnologieEngineering-ArtikelDatabasesTechnologyEngineering ArticlesGraphModeling
Leseoptionen
Einführung
Graphdatenbanken sind speziell für die Speicherung und Abfrage stark vernetzter Daten konzipiert. Während sich relationale Datenbanken bei tabellarischen Daten mit bekannten Beziehungen auszeichnen, zeichnen sich Diagrammdatenbanken aus, wenn Beziehungen genauso wichtig sind wie die Daten selbst – soziale Netzwerke, Empfehlungsmaschinen, Betrugserkennung, Wissensgraphen und Lieferketten.
Die grundlegende Erkenntnis: In vielen Bereichen SIND die Verbindungen zwischen Entitäten die Daten, und Diagrammdatenbanken machen diese Verbindungen zu einem erstklassigen Bürger.
Graphdatenbankkonzepte
Eigenschaftsdiagrammmodell
┌──────────────────┐
│ Person │
│ name: "Alice" │
│ age: 30 │
└────────┬─────────┘
│
┌────────▼─────────┐
│ KNOWS │
│ since: 2020 │
│ type: "friend" │
└────────┬─────────┘
│
┌────────▼─────────┐
│ Person │
│ name: "Bob" │
│ age: 32 │
└──────────────────┘
Drei Kernkomponenten:
| Komponente | Beschreibung | Beispiel |
|---|---|---|
| Knoten (Scheitelpunkt) | Eine Entität im Diagramm | Person, Unternehmen, Produkt |
| Edge (Beziehung) | Eine Verbindung zwischen zwei Knoten | WEISS, WORKS_AT, GEKAUFT |
| Eigentum | Attribute an Knoten oder Kanten | Name: „Alice“, seit: 2020 |
Relational vs. Graph
Beziehungen in SQL abfragen:
-- Find friends of friends who work at Google
SELECT DISTINCT p3.name
FROM persons p1
JOIN friendships f1 ON p1.id = f1.person_id
JOIN persons p2 ON f1.friend_id = p2.id
JOIN friendships f2 ON p2.id = f2.person_id
JOIN persons p3 ON f2.friend_id = p3.id
JOIN employment e ON p3.id = e.person_id
JOIN companies c ON e.company_id = c.id
WHERE p1.name = 'Alice'
AND c.name = 'Google';
Gleiche Abfrage in Cypher (Neo4j):
MATCH (alice:Person {name: "Alice"})
-[:KNOWS*2]->
(friend_of_friend:Person)
MATCH (friend_of_friend)-[:WORKS_AT]->(google:Company {name: "Google"})
RETURN DISTINCT friend_of_friend.name
Hauptunterschied: SQL jongliert mit mehreren JOINs. Graphdurchläufe stimmen auf natürliche Weise mit Mustern überein.
Graph-Abfragesprachen
Cypher (Neo4j) – Deklarativer Mustervergleich
// Create nodes and relationships
CREATE (alice:Person {name: "Alice", age: 30})
CREATE (bob:Person {name: "Bob", age: 32})
CREATE (alice)-[:KNOWS {since: 2020}]->(bob)
// Find friends of friends who bought products in the last month
MATCH (user:Person {id: $userId})
-[:KNOWS]->
(friend:Person)
-[:PURCHASED]->
(product:Product)
WHERE product.purchased_at > datetime() - duration('P1M')
RETURN product.name, count(*) as purchase_count
ORDER BY purchase_count DESC
LIMIT 10
// Shortest path between two people
MATCH p = shortestPath(
(alice:Person {name: "Alice"})-[:KNOWS*]-(bob:Person {name: "Bob"})
)
RETURN length(p) as degrees_of_separation,
[node IN nodes(p) | node.name] as path
Gremlin (Apache TinkerPop) – Imperative Graph Traversal
// Same query in Gremlin
g.V().has('Person', 'name', 'Alice')
.repeat(out('KNOWS')).times(2)
.out('WORKS_AT')
.has('Company', 'name', 'Google')
.values('name')
.dedup()
SPARQL (RDF) – Semantisches Web
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX org: <http://www.w3.org/ns/org#>
SELECT ?name WHERE {
?alice foaf:name "Alice" ;
foaf:knows ?friend .
?friend foaf:knows ?friend_of_friend .
?friend_of_friend org:memberOf ?company .
?company org:legalName "Google" .
?friend_of_friend foaf:name ?name .
}
Vergleich der Diagrammdatenbanken
| Funktion | Neo4j | Amazon Neptun | ArangoDB | JanusGraph | Dgraph |
|---|---|---|---|---|---|
| Abfragesprache | Chiffre | Gremlin/SPARQL | AQL | Gremlin | GraphQL+ |
| Lagerung | Natives Diagramm | RDF/Eigenschaft | Multi-Modell | Cassandra/HBase | Dachs |
| Clusterbildung | Unternehmen | Verwaltet | Ja | Ja | Ja |
| SÄURE | Ja | Ja | Ja | Pro Speicher | Ja |
| Kostenloses Kontingent | Community (1 Knoten) | Pay-as-you-go | Open Source | Open Source | Open Source |
| Am besten für | Unternehmensdiagramme | AWS-Ökosystem | Multi-Modell | Big-Data-Diagramme | Hohe Leistung |
| Vektorsuche | ✅ (5.x+) | ❌ | ✅ | ❌ | ❌ |
Anwendungsfälle
1. Soziale Netzwerke und Empfehlungen
(User:Alice)-[:KNOWS]->(User:Bob)
(User:Alice)-[:LIKES]->(Movie:Inception)
(User:Bob)-[:LIKES]->(Movie:Inception)
(User:Charlie)-[:KNOWS]->(User:Alice)
Empfehlungsabfrage – „Filme, die Freunden von Freunden gefallen“:
MATCH (me:User {id: $userId})
-[:KNOWS*1..2]-
(other:User)
-[:LIKES]->
(movie:Movie)
WHERE NOT EXISTS {
(me)-[:LIKES]->(movie)
OR (me)-[:DISLIKES]->(movie)
}
RETURN movie.title, count(DISTINCT other) as friend_count,
avg(other.rating) as avg_rating
ORDER BY friend_count DESC, avg_rating DESC
LIMIT 20
2. Betrugserkennung
Betrugsringe weisen komplexe, nicht offensichtliche Muster auf. Diagrammabfragen erkennen sie effizient:
// Detect potential fraud rings:
// Multiple accounts sharing same device, IP, or phone
MATCH (account:Account)
-[:USED_DEVICE]->(device:Device)<-[:USED_DEVICE]-
(other:Account),
(account)-[:USED_IP]->(ip:IPAddress)<-[:USED_IP]-
(other)
WHERE account.id <> other.id
AND account.created_at > datetime() - duration('P7D')
RETURN account.id, other.id, device.device_id, ip.address,
count(*) as connection_count
ORDER BY connection_count DESC
LIMIT 100
Statistiken zur Betrugserkennung:
| Metrisch | Vor dem Diagramm | Nach der Grafik |
|---|---|---|
| Erkennungsrate | 65% | 93% |
| Falsch-Positiv-Rate | 8% | 2% |
| Untersuchungszeit pro Fall | 45 Min | 5 Min |
3. Wissensgraphen
Wissensgraphen verbinden strukturierte und unstrukturierte Daten zu einem einheitlichen Bedeutungsnetz:
// Create a knowledge graph from documents
LOAD CSV WITH HEADERS FROM 'file:///entities.csv' AS row
CREATE (e:Entity {
id: row.id,
name: row.name,
type: row.type,
description: row.description
});
LOAD CSV WITH HEADERS FROM 'file:///relationships.csv' AS row
MATCH (a:Entity {id: row.source_id})
MATCH (b:Entity {id: row.target_id})
CALL apoc.create.relationship(a, row.relationship_type, {
source_document: row.document,
confidence: toFloat(row.confidence)
}) YIELD rel
RETURN count(*);
// Query: "How does Product X relate to Regulation Y?"
MATCH path = shortestPath(
(product:Entity {name: "Product X"})
-[:AFFECTS|REGULATES|DEPENDS_ON|MANUFACTURED_BY*]-
(regulation:Entity {name: "Regulation Y"})
)
RETURN [node IN nodes(path) | {name: node.name, type: node.type}],
[rel IN relationships(path) | type(rel)]
4. Lieferkette
// Find all suppliers that feed into a critical component
MATCH (component:Part {name: "Critical Microchip"})
<-[:PRODUCES]-
(:Factory)
-[:SOURCES_FROM]->
(supplier:Supplier)
-[:SUPPLIED_BY]->
(sub_supplier:Supplier)
WHERE sub_supplier.location IN ["Region_A", "Region_B"]
RETURN component.name, supplier.name, sub_supplier.name,
sub_supplier.location
// Impact analysis: "If Supplier X fails, which products are affected?"
MATCH (failing:Supplier {id: $supplierId})
<-[:SUPPLIED_BY]-*
(factory:Factory)
-[:PRODUCES]->
(product:Product)
RETURN product.name, product.revenue,
count(DISTINCT factory) as factories_affected
ORDER BY product.revenue DESC
Interna der Graphdatenbank
Indexfreie Nachbarschaft
Der grundlegende Leistungsvorteil nativer Graphdatenbanken: Jeder Knoten zeigt direkt auf seine verbundenen Nachbarn. Für Durchläufe sind keine Indexsuchen erforderlich.
Relational Database: Graph Database:
┌────────┐
Find friends: │ Alice │──┐
1. Index lookup on person_id ──┐ │ │ │
2. Index lookup on friend_id ──┤ └────────┘ │
3. Join results ──┤ │ │
4. Fetch friend data ──┤ ┌──▼─────┐ │
│ │ Bob │◄─┘
O(log N) per hop │ │ │
│ └────────┘
│
For 6 degrees of separation: │ O(1) per traversal hop
O(log N × 6) = O(log N) │ O(6) = O(1)
│
│ For 6 hops: 6 pointer dereferences
Graphpartitionierung
Bei verteilten Graphdatenbanken ist die Partitionierung eine Herausforderung:
| Strategie | Beschreibung | Problem |
|---|---|---|
| Kantenschnitt | Nach Scheitelpunkt geteilt, Kanten kreuzen Partitionen | Viele partitionsübergreifende Durchquerungen |
| Scheitelschnitt | Nach Kante teilen, Scheitelpunkt replizieren | Konsistenzaufwand |
| Hash-Partitionierung | Hash-Scheitelpunkte zu Partitionen | Zufällig – schlechte Lokalität |
| Bereichspartitionierung | Partition nach Eigenschaftswert | Skew, wenn die Daten nicht einheitlich sind |
Erweiterte Diagrammmuster
Zeitdiagramme (Zeitreiseabfragen)
// Property graph with versioned edges
MATCH (employee:Employee {id: $empId})
-[assignment:ASSIGNED_TO]->(project:Project)
WHERE assignment.from_date <= date("2026-01-15")
AND (assignment.to_date IS NULL OR assignment.to_date >= date("2026-01-15"))
RETURN employee.name, project.name, assignment.role
// What was the org structure on Jan 1, 2025?
MATCH (manager:Employee)
-[reports:MANAGES]->(report:Employee)
WHERE reports.effective_from <= date("2025-01-01")
AND (reports.effective_to IS NULL OR reports.effective_to > date("2025-01-01"))
RETURN manager.name, collect(report.name) as reports
Graphalgorithmen (Neo4j GDS)
from neo4j import GraphDatabase
from graphdatascience import GraphDataScience
gds = GraphDataScience("bolt://localhost:7687", auth=("neo4j", "password"))
# Create in-memory graph
G, result = gds.graph.project(
"myGraph",
["Person", "Company"],
["KNOWS", "WORKS_AT"]
)
# PageRank — find influential people
pagerank = gds.pageRank.stream(G)
influencers = pagerank.sort_values('score', ascending=False).head(10)
# Community detection (Louvain) — find clusters
communities = gds.louvain.stream(G)
Diagramm + Vektorsuche (Hybrid)
Moderne Graphdatenbanken (Neo4j 5.x+) unterstützen sowohl die Graph- als auch die Vektorsuche:
// Find similar products using vector embeddings,
// then traverse the recommendation graph
CALL db.index.vector.queryNodes(
'product-embeddings',
10,
$query_embedding
) YIELD node AS similar_product, score
MATCH (similar_product)-[:ALSO_BOUGHT]->(recommended:Product)
WHERE recommended.rating > 4.0
RETURN recommended.name, recommended.price, score
ORDER BY score DESC, recommended.rating DESC
LIMIT 20
Anti-Patterns für Graphdatenbanken
| Anti-Muster | Warum es weh tut | Besserer Ansatz |
|---|---|---|
| Globale Operationen | „MATCH (n) WHERE n.property“ scannt alle Knoten | Index hinzufügen: „CREATE INDEX FOR (n:Label) ON (n.property)“. |
| Tiefe unbegrenzte Durchquerungen | MATCH (a)-[*]->(b) ohne Begrenzung |
Geben Sie die Tiefe an: „[*1..5]“. |
| Superknoten | Ein Knoten mit Millionen von Kanten | Brechen Sie in Zwischenknoten auf und nutzen Sie Zeitgrenzen |
| Fehlende Richtung | Bidirektionale Kanten verursachen eine doppelte Durchquerung | Definieren Sie eine klare Richtung und bewegen Sie sich effizient |
| Übernormalisierung | Knoten für einfache Attribute erstellen | Verwenden Sie stattdessen Knoteneigenschaften |
Wann sollte eine Diagrammdatenbank verwendet werden?
Verwenden Sie das Diagramm, wenn:
- Beziehungen sind erstklassig – die Verbindungen SIND die Daten.
- Die Durchlauftiefe ist variabel – 2-Hop- und 6-Hop-Abfragen ändern sich dynamisch.
- Das Schema entwickelt sich häufig weiter – es werden spontan neue Beziehungstypen hinzugefügt.
- Mustervergleich ist das Abfragemuster – „Pfade finden, die wie X aussehen.“
- Komplexe Join-Ketten – 5+ JOINs in SQL deuten darauf hin, dass ein Diagramm möglicherweise besser ist.
Verwenden Sie kein Diagramm, wenn:
- Die Daten sind rein tabellarisch – Verkaufsaufzeichnungen, Transaktionsprotokolle.
- Aggregatintensive Arbeitslasten – „Gesamtumsatz nach Region“ (SQL/Spaltenspeicher ist besser).
- Einfaches CRUD nach ID – „Benutzer per E-Mail finden“ (relationale Datenbank ist in Ordnung).
- Punktabfragen mit hohem Volumen – Millionen einfacher Suchvorgänge pro Sekunde.
Fazit
Graphdatenbanken zeichnen sich dadurch aus, dass Beziehungen komplex, variabel und für die Domäne von zentraler Bedeutung sind. Sie sind kein Ersatz für relationale Datenbanken – sie sind ein ergänzendes Werkzeug für bestimmte Problembereiche.
- Soziale Systeme und Empfehlungssysteme – durchqueren Sie Diagramme von Freunden auf natürliche Weise.
- Betrugserkennung – Finden Sie nicht offensichtliche Verbindungen in Finanznetzwerken.
- Wissensgraphen – verbinden Sie Daten aus verschiedenen Quellen in einem einheitlichen Modell.
- Lieferkette und Logistik – Modellieren Sie komplexe mehrstufige Beziehungen.
- Netzwerk- und IT-Betrieb – Abhängigkeitsdiagramme, Ursachenanalyse.
Best Practice: Beginnen Sie mit Neo4j (dem ausgereiftesten Ökosystem), verwenden Sie Cypher für Abfragen und kombinieren Sie es mit der Vektorsuche für KI-gestützte Diagrammanwendungen. Halten Sie die Durchquerungstiefe begrenzt, indizieren Sie beschriftete Eigenschaften und überwachen Sie das Superknotenwachstum.
Kommentare
0 KommentareNoch keine freigegebenen Kommentare sichtbar. Neue Antworten können moderiert werden.