Artikel
Datenbankreplikation und Hochverfügbarkeit
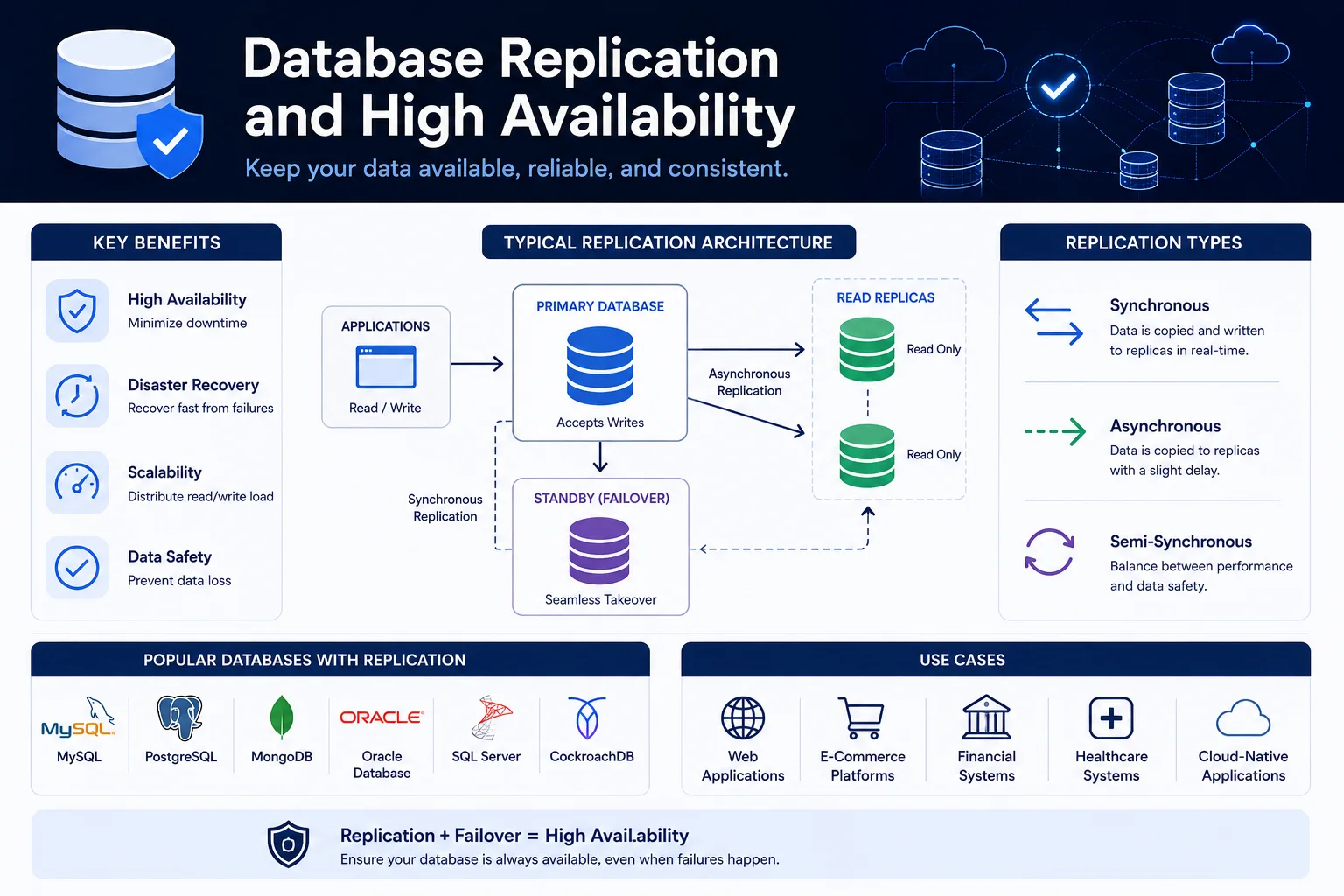
Bei der Datenbankreplikation handelt es sich um den Prozess des Kopierens und Verwaltens von Datenbankdaten auf mehreren Servern. Es ist die Grundlage für Hochverfügbarkeit (HA), Disaster Recovery (DR), Leseskalierung und geografische Verteilung.
4 Min. LesezeitSprache: DE DeutschKostenlos0 Claps0 Kommentare
TechnologieEngineering-ArtikelDatabaseHighDatabasesTechnologyEngineering ArticlesReplication
Leseoptionen
Einführung
Bei der Datenbankreplikation handelt es sich um den Prozess des Kopierens und Verwaltens von Datenbankdaten auf mehreren Servern. Es ist die Grundlage für Hochverfügbarkeit (HA), Disaster Recovery (DR), Leseskalierung und geografische Verteilung.
Keine Datenbank ist wirklich „immer verfügbar“ – Hardware fällt aus, Netzwerkpartitionierung, Software stürzt ab. Durch die Replikation wird sichergestellt, dass beim Ausfall einer Datenbankinstanz eine andere mit minimaler oder keiner Ausfallzeit übernehmen kann.
Warum Replikation?
| Ziel | Beschreibung | Replikationsansatz |
|---|---|---|
| Hohe Verfügbarkeit | Das System bleibt nach Ausfällen weiterhin erreichbar | Automatisches Failover zum Replikat |
| Notfallwiederherstellung | Überstehen Sie Ausfälle auf Regionsebene | Georedundante Replikate |
| Skalierung lesen | Behandeln Sie mehr Leseabfragen | Verteilen Sie Lesevorgänge an Replikate |
| Sicherung | Point-in-Time-Wiederherstellung ohne Last | Für Backups verwendetes Replikat |
| Geografische Verteilung | Geringe Latenz für globale Benutzer | Lokale Replikate in jeder Region |
| Wartung | Upgrades ohne Ausfallzeiten | Failover während der Wartung |
Replikationsarchitekturen
1. Einzelner Anführer (Master-Replikat)
┌──────────────────┐
│ Master Node │
│ (reads + writes)│
└────────┬─────────┘
│ write-ahead log (WAL)
│
┌───────────────────┼───────────────────┐
│ │ │
┌────▼────┐ ┌────▼────┐ ┌────▼────┐
│Replica 1│ │Replica 2│ │Replica 3│
│(read │ │(read │ │(read │
│ only) │ │ only) │ │ only) │
└─────────┘ └─────────┘ └─────────┘
Vorteile:
- Einfach einzurichten und zu verstehen.
- Konsistente Lesevorgänge vom Master.
- Gut unterstützt von allen Datenbanken.
Nachteile:
- Schreibengpass (einzelner Master).
- Replikationsverzögerung (asynchron) oder Schreiblatenz (synchronisiert).
- Manuelles oder automatisiertes Failover erforderlich.
-- PostgreSQL streaming replication setup
-- Primary: postgresql.conf
wal_level = replica
max_wal_senders = 10
wal_keep_size = 1024 -- MB
-- Replica: postgresql.conf
primary_conninfo = 'host=primary.example.com port=5432 user=replicator'
-- Create replication slot on primary
SELECT pg_create_physical_replication_slot('replica_1');
2. Multi-Leader (Aktiv-Aktiv)
┌──────────────┐ ┌──────────────┐
│ Leader A │◄───────────►│ Leader B │
│ (US-East) │ sync WAL │ (EU-West) │
└──────┬───────┘ └──────┬───────┘
│ │
┌────▼────┐ ┌────▼────┐
│Replica A│ │Replica B│
└─────────┘ └─────────┘
Vorteile:
- Schreibvorgänge werden an mehreren Standorten akzeptiert (geringere Latenz).
- Kein Single Point of Failure für Schreibvorgänge.
- Gut für die geografische Verteilung.
Nachteile:
- Schreibkonflikte müssen gelöst werden (Last-Writer-Wins, CRDTs, Anwendungslogik).
- Komplexe Konfliktlösung.
- Nicht alle Datenbanken unterstützen Multi-Leader.
# Multi-leader with conflict resolution (CouchDB, PostgreSQL BDR)
conflict_resolution:
strategy: "last_writer_wins" # Default — may lose data
# or: "application_merge" # Application handles conflicts
# or: "crdt" # Automatic conflict-free merging
3. Führungslos (Quorumbasiert)
Client ──► Write to all 3 nodes (W=2, R=2)
┌────────┐ ┌────────┐ ┌────────┐
│ Node 1 │ │ Node 2 │ │ Node 3 │
└────────┘ └────────┘ └────────┘
│ │ │
└─────────────┼─────────────┘
│
Client ◄────── Read from 2 nodes, compare versions (R=2)
Amazon DynamoDB / Cassandra-Modell:
- Jeder Knoten kann Lese- und Schreibvorgänge akzeptieren.
- W + R > N (Gesamtknoten) garantiert Konsistenz.
- Verwendet Vektoruhren zur Versionsverfolgung.
Vorteile:
- Kein Single Point of Failure.
- Extrem hohe Verfügbarkeit.
- Lineare Skalierbarkeit.
Nachteile:
- Endgültige Konsistenz standardmäßig.
- Komplexe Konfliktlösung (Vektoruhren).
- Nicht geeignet für relationale Daten mit Fremdschlüsseln.
Synchrone vs. asynchrone Replikation
| Aspekt | Synchron | Asynchron |
|---|---|---|
| Datenverlust bei Failover | Null (RPO = 0) | Etwas Datenverlust (RPO > 0) |
| Schreiblatenz | Höher (auf Replikat-ACK warten) | Senken (sofort quittieren) |
| Konsistenz beim Lesen nach dem Schreiben | Garantiert | Möglicherweise veraltete Lesevorgänge aus der Replik |
| Netzwerkanforderung | Geringe Latenz, zuverlässig | Verträgt höhere Latenz |
| Replika-Auswirkung | Replikatfehler blockieren Schreibvorgänge | Replikatfehler haben keine Auswirkungen |
-- PostgreSQL: synchronous replication
-- primary.conf
synchronous_standby_names = 'FIRST 1 (replica_1, replica_2)'
-- Now every write waits for at least one synchronous replica
-- Acknowledgment before returning COMMIT to client
Failover-Strategien
Manuelles Failover
# PostgreSQL manual failover
# On replica:
pg_ctl promote -D /var/lib/postgresql/data
# Update application connection string
# point at new primary
Ausfallzeit: Minuten bis Stunden (menschliche Reaktionszeit).
Automatisches Failover (HA Tools)
# Patroni — PostgreSQL HA
scope: production
namespace: /db/
consul:
host: consul.example.com:8500
postgresql:
use_pg_rewind: true
parameters:
max_connections: 200
# On primary failure:
# 1. Patroni detects primary is down
# 2. Promotes most up-to-date replica
# 3. Updates Consul with new primary address
# 4. All clients automatically reconnect
| Werkzeug | Datenbank | Mechanismus | Failover-Zeit |
|---|---|---|---|
| Patroni | PostgreSQL | Consul/etcd + REST-API | 10-30 Sekunden |
| Orchestrator | MySQL | Floßbasiert | 5-15 Sekunden |
| Redis Sentinel | Redis | Klatschprotokoll | 10-30 Sekunden |
| MongoDB-Replikatset | MongoDB | Interne Wahl | < 10 Sekunden |
| Kubernetes-Betreiber | Verschiedene | K8s-nativ | Hängt von der Sonde ab |
VIP-/DNS-Failover
# Keepalived — Virtual IP failover
vrrp_instance VI_1 {
interface eth0
state BACKUP
virtual_router_id 51
priority 100
advert_int 1
virtual_ipaddress {
10.0.0.100/24 # Floating IP
}
track_script {
chk_postgres
}
}
Replikationsverzögerung und Konsistenz
Ursachen für Replikationsverzögerungen
| Ursache | Beschreibung | Schadensbegrenzung |
|---|---|---|
| Netzwerklatenz | Abstand zwischen Knoten | Kollozieren oder nutzen Sie die WAN-Optimierung |
| Große Transaktionen | Lässt sich nur langsam auf Replikate anwenden | Brechen Sie in kleinere Transaktionen auf |
| CPU-Sättigung | Replica kann nicht mithalten | Skalieren Sie Replika-Hardware |
| Abfragen mit langer Laufzeit | Sperrt die Replik | Statement_timeout festlegen |
| DDL-Operationen | Schemaänderungen sperren Tabellen | Verwenden Sie gleichzeitiges DDL |
Überwachen der Replikationsverzögerung
-- PostgreSQL lag monitoring
SELECT application_name,
pg_size_pretty(pg_wal_lsn_diff(
pg_current_wal_lsn(), replay_lsn
)) as lag_bytes,
ROUND(EXTRACT(EPOCH FROM NOW() - pg_last_xact_replay_timestamp()))
as lag_seconds
FROM pg_stat_replication;
-- Expected: < 1 second (async), < 10ms (sync)
Umgang mit veralteten Lesevorgängen
# Application pattern: "read-your-writes" consistency
class ConsistentDBClient:
def __init__(self, master, replica):
self.master = master
self.replica = replica
def write(self, key, value):
# Write to master, record timestamp
result = self.master.execute("INSERT ...")
self._last_write_timestamp = time.time()
return result
def read(self, key):
# Read from replica, but verify freshness
data = self.replica.execute(f"SELECT * FROM ... WHERE id='{key}'")
# Check if we just wrote this record
stale_time = time.time() - self._last_write_timestamp
if stale_time < 1.0: # Within last second
# This is a recent write — read from master for consistency
if data is None:
data = self.master.execute(f"SELECT ... WHERE id='{key}'")
return data
Backup und Notfallwiederherstellung
Backup-Strategien
| Strategie | RPO | RTO | Lagerung | Kosten |
|---|---|---|---|---|
| Tägliches Voll-Backup | 24 Stunden | Stunden | Hoch | Niedrig |
| WAL-Archivierung | Minuten | Variabel | Mittel | Niedrig |
| Kontinuierliche Archivierung | < 1 Minute | Minuten | Hoch | Mittel |
| Replikat zur Sicherung | Sekunden | Schnell | Hoch | Mittel |
| Mehrregionales Replikat | < 1 Sekunde | Am schnellsten | Sehr hoch | Hoch |
# PostgreSQL continuous archiving
archive_mode = on
archive_command = 'pgbackrest --stanza=prod archive-push %p'
# Point-in-time recovery
pgbackrest --stanza=prod --type=time \
--target="2026-05-24 14:30:00+00" \
--target-action=promote restore
Disaster-Recovery-Stufen
RPO: Recovery Point Objective (how much data can you lose)
RTO: Recovery Time Objective (how fast must you recover)
Tier 1 (Mission Critical): RPO < 1 minute, RTO < 5 minutes
Multi-region synchronous replication
Automatic failover
Regularly tested
Tier 2 (Business Critical): RPO < 1 hour, RTO < 30 minutes
Async replication to DR region
Semi-automated failover
Quarterly tests
Tier 3 (Standard): RPO < 24 hours, RTO < 4 hours
Daily backups + WAL archiving
Manual restore
Annual tests
Lesen Sie Skalierung mit Replikaten
Load-Balancing-Lesevorgänge
import random
from itertools import cycle
class ReadLoadBalancer:
def __init__(self, replicas: list[str]):
self.replicas = cycle(replicas)
def get_reader(self) -> str:
return next(self.replicas)
def execute_query(self, query: str, is_read: bool = True):
if is_read:
conn = self.get_reader()
else:
conn = "master"
return execute_on(conn, query)
Proxy-basierter Lastenausgleich
# PgBouncer or HAProxy configuration
# Routes reads to replicas, writes to master
listen pg_cluster
bind *:5432
mode tcp
acl is_write method POST
acl is_write query ^(INSERT|UPDATE|DELETE)
use_backend master if is_write
default_backend replicas
backend master
server pg-master 10.0.0.1:5432 check
backend replicas
server pg-replica1 10.0.0.2:5432 check
server pg-replica2 10.0.0.3:5432 check
server pg-replica3 10.0.0.4:5432 check
Datenbankspezifische Replikation
PostgreSQL
| Funktion | Beschreibung |
|---|---|
| Streaming-Replikation | Physisches WAL-Streaming zu Replikaten |
| Logische Replikation | Replikation auf Tabellenebene (PostgreSQL 10+) |
| Kaskadierende Replikation | Das Replikat kann andere Replikate bedienen |
| Synchrone Replikation | Konfigurierbare Synchronisierung pro Transaktion |
| pg_rewind | Schnelle Neusynchronisierung nach Split-Brain |
MySQL
| Funktion | Beschreibung |
|---|---|
| Gruppenreplikation | Multi-Master, integrierte Gruppenmitgliedschaft |
| InnoDB-Cluster | Komplette HA-Lösung mit MySQL-Router |
| Semisync-Replikation | Mindestens eine Replik bestätigt |
| GTID-basierte Replikation | Globale Transaktions-IDs zur Sicherheit |
MongoDB
| Funktion | Beschreibung |
|---|---|
| Replika-Set | Automatische Wahl, bis zu 50 Mitglieder |
| Besorgnis schreiben | Konfigurierbare Bestätigungsebene |
| Lesepräferenz | Leiten Sie Lesevorgänge zum nächstgelegenen Replikat weiter |
| Streams ändern | Echtzeit-CDC von oplog |
Split-Brain-Problem
Split-Brain tritt auf, wenn die Netzwerkpartition dazu führt, dass beide Knoten glauben, sie seien der Master:
Before partition:
Master A ◄──► Replica B
After partition:
Master A |X| Replica B (promoted to master)
(believes it |X| (believes it is master)
is master) |X|
When partition heals: two masters, inconsistent data
Prävention:
- Mehrheitsquorum – Nur die Seite mit > N/2 Knoten kann Master sein.
- STONITH (Den anderen Knoten in den Kopf schießen) – Töte den alten Meister.
- Fencing – Widerrufen Sie den Zugriff auf den gemeinsam genutzten Speicher.
- Leasingbasiert – Lease läuft aus und muss erneuert werden.
Fazit
Die Datenbankreplikation ist für Produktionssysteme, die Verfügbarkeit, Haltbarkeit und Leistung erfordern, von entscheidender Bedeutung:
| Maßstab | Ansatz |
|---|---|
| Klein (einzelner Knoten) | Tägliche Backups auf S3 |
| Mittel (1–10 Millionen Benutzer) | Einzelner Master + 1–2 Replikate, automatisiertes Failover |
| Groß (10–100 Millionen Benutzer) | Multi-Leader oder Sharded, geografisch verteilt |
| Global (über 100 Millionen Benutzer) | Multiregionale Aktiv-Aktiv-, CRDTs oder Last-Writer-Wins |
Grundprinzipien:
- Failover testen – Wenn Sie es nicht getestet haben, funktioniert es nicht.
- Überwachungsverzögerung – Replikationsverzögerung ist die häufigste Ursache für Dateninkonsistenz.
- Split-Brain planen – Überlegen Sie sich eine Strategie, bevor es passiert.
- Passen Sie RPO/RTO an die Geschäftsanforderungen an – Nicht jedes System benötigt keinen Datenverlust.
- Alles automatisieren – Manuelle Wiederherstellung führt zu Fehlern und Ausfallzeiten.
Die Replikation ist keine „Set-and-Forget“-Funktion – sie erfordert kontinuierliche Überwachung, Tests und Optimierung.
Kommentare
0 KommentareNoch keine freigegebenen Kommentare sichtbar. Neue Antworten können moderiert werden.