مقال
قواعد البيانات في الذاكرة والتخزين المؤقت: السرعة على نطاق واسع
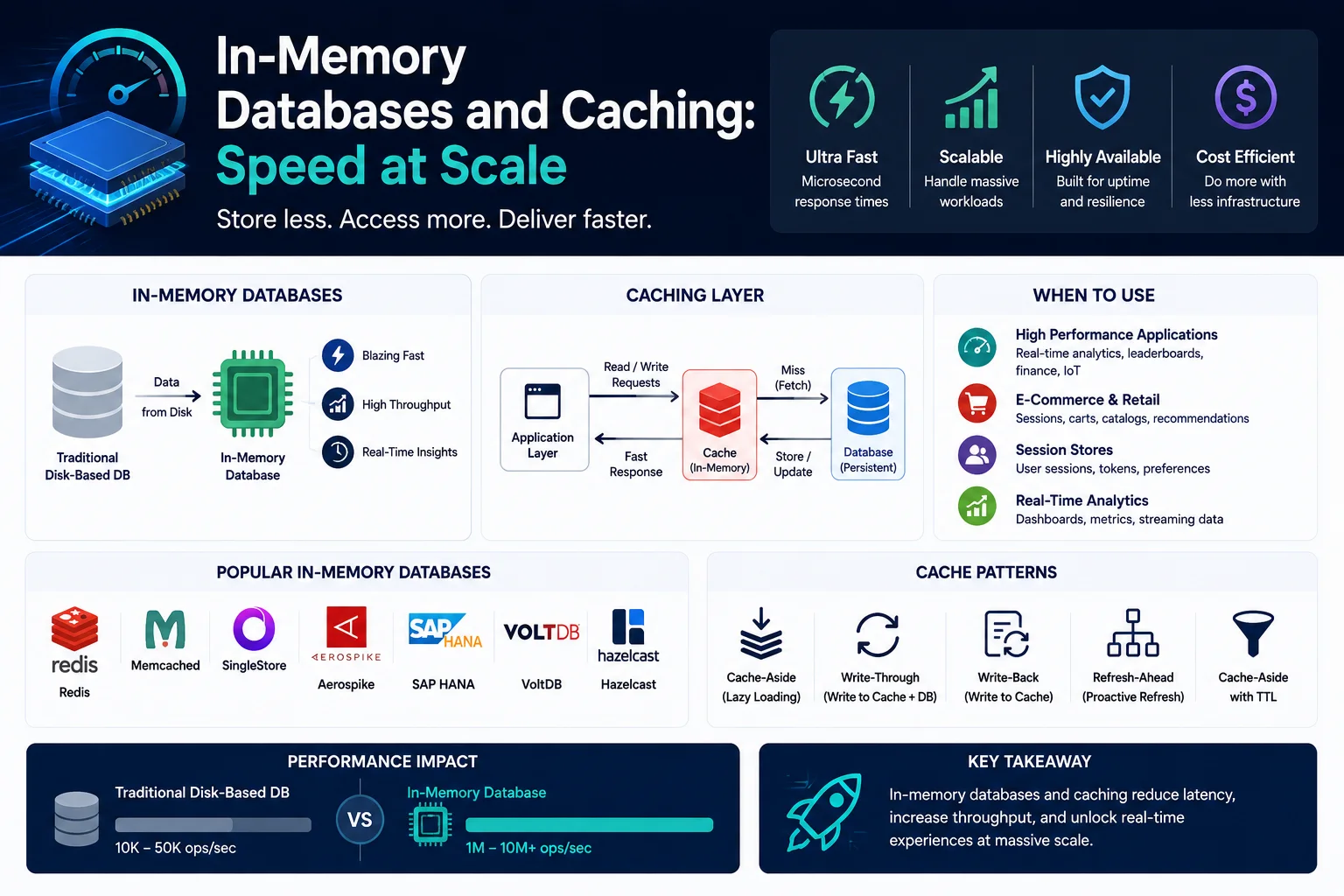
تقوم قواعد البيانات الموجودة في الذاكرة بتخزين البيانات بشكل أساسي في ذاكرة الوصول العشوائي (RAM) بدلاً من تخزينها على القرص. يؤدي هذا إلى التخلص من زمن استجابة الإدخال/الإخراج للقرص، مما يوفر أوقات استجابة بالميكروثانية - بأوامر من حيث الحجم أسرع من قواعد البيانات التقليدية المستندة إلى القرص.
3 دقيقة قراءةاللغة: AR العربيةمجاني0 تصفيقات0 تعليقات
التقنيةمقالات هندسيةCachingDatabasesTechnologyEngineering ArticlesMemory
خيارات القراءة
مقدمة
تقوم قواعد البيانات الموجودة في الذاكرة بتخزين البيانات بشكل أساسي في ذاكرة الوصول العشوائي (RAM) بدلاً من تخزينها على القرص. يؤدي هذا إلى التخلص من زمن استجابة الإدخال/الإخراج للقرص، مما يوفر أوقات استجابة بالميكروثانية - بأوامر من حيث الحجم أسرع من قواعد البيانات التقليدية المستندة إلى القرص.
لا تعد قواعد البيانات الموجودة في الذاكرة بديلاً لقواعد البيانات التقليدية، بل إنها مكملة لها. إنهم يتفوقون في حالات الاستخدام التي تتطلب زمن وصول منخفض للغاية، وإنتاجية عالية، ومعالجة البيانات في الوقت الفعلي: التخزين المؤقت، وإدارة الجلسة، والتحليلات في الوقت الفعلي، ولوحات المتصدرين، وتحديد المعدل، ووساطة الرسائل.
في الذاكرة مقابل قواعد البيانات المستندة إلى القرص
| الجانب | قاعدة بيانات في الذاكرة | قاعدة البيانات المستندة إلى القرص |
|---|---|---|
| ** التخزين الأساسي ** | ذاكرة الوصول العشوائي | SSD / الأقراص الصلبة |
| ** قراءة الكمون ** | < 1 مللي ثانية (0.1 مللي ثانية نموذجيًا) | 1-10 مللي ثانية (SSD)، 5-20 مللي ثانية (HDD) |
| ** كتابة الإنتاجية ** | 100 ألف - 1 مليون+ عمليات/ثانية | 1K-100K العمليات/ثانية |
| ** ثبات البيانات ** | اختياري (لقطات، AOF) | مثابرة دائما |
| السعة | ذاكرة الوصول العشوائي محدودة (جيجابايت - تيرابايت) | محدودية القرص (TBs-PBs) |
| التكلفة لكل جيجابايت | ~10-50 دولارًا/جيجابايت | ~0.10 دولار-1/جيجابايت |
| تعقيد الاستعلام | القيمة الأساسية، والهياكل البسيطة | الصلات المعقدة والتجمعات |
| المتانة | قابلة للتكوين (مقايضة fsync) | ضمانات ACID الكاملة |
Redis: المتجر الأكثر شعبية في الذاكرة
هياكل البيانات
# Strings — most basic
SET user:100:name "Alice"
GET user:100:name # "Alice"
INCR page_counter # 1
INCRBY page_counter 5 # 6
# Lists — ordered, push/pop from ends
LPUSH notifications:101 "New message"
RPOP notifications:101 # "New message"
LLEN notifications:101 # Length
# Sets — unordered, unique members
SADD user:100:tags "redis" "python" "database"
SMEMBERS user:100:tags # All members
SISMEMBER user:100:tags "python" # 1 (true)
SINTER user:100:tags user:200:tags # Intersection
# Sorted Sets — scored, ordered
ZADD leaderboard 1000 "player1"
ZADD leaderboard 2500 "player2" 900 "player3"
ZREVRANGE leaderboard 0 2 WITHSCORES # Top 3
# 1) "player2" (2500)
# 2) "player3" (900)
# 3) "player1" (1000)
# Hashes — structured objects
HSET user:100 name "Alice" age 30 email "alice@example.com"
HGETALL user:100
HINCRBY user:100 login_count 1
# Streams — append-only log (like Kafka)
XADD events * type "login" user_id "100"
XRANGE events - + COUNT 10
# Geospatial — location-based
GEOADD locations 13.361389 38.115556 "Palermo"
GEORADIUS locations 15 37 100 km # Cities within 100km
خيارات الثبات
| الوضع | كيف يعمل | المتانة | تأثير الأداء |
|---|---|---|---|
| RDB (لقطة) | تفريغ كامل دوري على القرص | تفريغ الماضي المفقود | منخفض (شوكة + كتابة) |
| ** AOF (إلحاق فقط) ** | تم تسجيل كل كتابة | قابل للتكوين: دائمًا/ثانية/لا | متوسط |
| RDB + AOF | كلاهما مجتمعين | عالية | متوسط |
| ** لا إصرار ** | ذاكرة الوصول العشوائي فقط، لا يوجد قرص الإدخال/الإخراج | لا شيء عند إعادة التشغيل | أفضل أداء |
# redis.conf — persistence configuration
save 900 1 # RDB: save if 1 key changed in 900 seconds
save 300 10 # save if 10 keys changed in 300 seconds
save 60 10000 # save if 10000 keys changed in 60 seconds
appendonly yes # Enable AOF
appendfsync everysec # fsync every second (best trade-off)
إنتاج هندسة Redis
نسخة رئيسية:
Client ──► Master (read/write)
│
┌────┴────┐
│ │
Replica1 Replica2 (read-only, failover targets)
Redis Sentinel — التوفر العالي:
┌──────────┐
│ Sentinel │ (monitors master, performs automatic failover)
└──────────┘
│
Client ──► Master ──► Replica1 ──► Replica2
│
(if master fails, Sentinel promotes a replica)
مجموعة Redis - المشاركة:
Client ──► Any node (auto-redirect to correct shard)
Shard 1 (Master A + Replica A')
Shard 2 (Master B + Replica B')
Shard 3 (Master C + Replica C')
Hash slots: 0-16383 distributed across shards
No central proxy — clients connect directly
أنماط التخزين المؤقت
ذاكرة التخزين المؤقت جانبا (تحميل كسول):
def get_user(user_id: str) -> dict:
# Try cache first
cached = redis.get(f"user:{user_id}")
if cached:
return json.loads(cached)
# Cache miss — load from database
user = db.query("SELECT * FROM users WHERE id = %s", user_id)
# Store in cache with TTL
redis.setex(f"user:{user_id}", 3600, json.dumps(user))
return user
الكتابة من خلال:
def update_user(user_id: str, data: dict):
# Update database
db.execute("UPDATE users SET ... WHERE id = %s", data, user_id)
# Update cache immediately
redis.setex(f"user:{user_id}", 3600, json.dumps(data))
الكتابة الخلفية (غير متزامن):
def write_behind(user_id: str, data: dict):
# First to cache (instant)
redis.setex(f"user:{user_id}", 3600, json.dumps(data))
# Queue for async database write
redis.lpush("write_queue", json.dumps({
'user_id': user_id,
'data': data,
'timestamp': time.time()
}))
# Background worker processes the queue
def write_worker():
while True:
task = json.loads(redis.brpop("write_queue")[1])
db.execute("UPDATE users SET ... WHERE id = %s",
task['data'], task['user_id'])
استراتيجيات التخزين المؤقت
استراتيجيات إبطال ذاكرة التخزين المؤقت
| استراتيجية | آلية | أفضل ل |
|---|---|---|
| ** على أساس TTL ** | ضبط مدة البقاء وانتهاء الصلاحية تلقائيًا | البيانات القديمة مقبولة |
| الكتابة | تحديث ذاكرة التخزين المؤقت في كل عملية كتابة | قراءة ثقيلة، كتابة خفيفة |
| الكتابة خلف | الكتابة غير المتزامنة إلى قاعدة البيانات | الكتابة الثقيلة، والاتساق في نهاية المطاف موافق |
| ** إبطال ذاكرة التخزين المؤقت ** | حذف/تحديث صريح | هناك حاجة إلى الاتساق القوي |
| ** على أساس الإصدار ** | يتضمن مفتاح ذاكرة التخزين المؤقت الإصدار | تغييرات المخطط |
سياسات الإخلاء
| السياسة | الوصف | حالة الاستخدام |
|---|---|---|
| LRU (الأقل استخدامًا مؤخرًا) | طرد أقدم مفتاح تم الوصول إليه | الغرض العام |
| LFU (الأقل استخدامًا) | طرد المفتاح الأقل وصولاً | أنماط الوصول مستقرة |
| TTL | مفاتيح انتهاء الصلاحية تلقائيًا | بيانات الجلسة، ذاكرة التخزين المؤقت المؤقتة |
| عشوائي | الإخلاء العشوائي | بسيطة ويمكن التنبؤ بها |
| ** لا يوجد إخلاء ** | خطأ في الإرجاع في الذاكرة الكاملة | يجب أن تبقى البيانات الهامة |
# Redis eviction policy
maxmemory 4gb
maxmemory-policy allkeys-lru # or: volatile-lru, allkeys-lfu, volatile-ttl
قواعد بيانات أخرى في الذاكرة
Memcached — بسيط، سريع، متعدد الخيوط
# Simple key-value (no persistence, no replication)
memcached -m 4096 -p 11211 -t 4
# Usage (similar to Redis but simpler)
set user:100 0 3600 15 # key, flags, ttl, byte_count
"Hello, World!"
get user:100
Redis مقابل Memcached:
| ميزة | ريديس | ميمكاشد |
|---|---|---|
| ** هياكل البيانات ** | السلاسل والقوائم والمجموعات والتجزئة والتدفقات وما إلى ذلك. | سلاسل فقط |
| ** الثبات ** | آر دي بي + AOF | لا شيء |
| ** النسخ ** | نسخة رئيسية + الكتلة | لا شيء |
| ** المعاملات ** | متعدد/EXEC، لوا | لا شيء |
| ** كفاءة الذاكرة ** | جيد (يحتوي على خيارات الضغط) | أفضل (أقل من النفقات العامة) |
| الخيوط | خيط واحد (حلقة الحدث) | متعدد الخيوط |
| ** حالة الاستخدام ** | ذاكرة التخزين المؤقت للأغراض العامة + هياكل البيانات | ذاكرة تخزين مؤقت بسيطة فقط |
اليعسوب – بديل Redis الحديث
# Dragonfly is multi-threaded (faster on multi-core CPUs)
dragonfly --bind 0.0.0.0 --port 6379
# Same Redis protocol, same clients
redis-cli SET key value
redis-cli GET key
Hazelcast وApache Ignite — شبكات البيانات الموزعة في الذاكرة
// Hazelcast — distributed cache with processing
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.map.IMap;
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IMap<String, User> cache = hz.getMap("users");
cache.put("user:100", user);
User cached = cache.get("user:100");
// Distributed computing
cache.executeOnKey("user:100", entry -> {
User user = entry.getValue();
user.incrementLoginCount();
entry.setValue(user);
return null;
});
حالات الاستخدام الشائعة
1. مخازن الجلسة
def create_session(user_id: str) -> str:
session_id = str(uuid.uuid4())
redis.setex(
f"session:{session_id}",
86400 * 7, # 7 days
json.dumps({
'user_id': user_id,
'created_at': time.time(),
'ip': request.remote_addr,
'user_agent': request.user_agent,
})
)
return session_id
def validate_session(session_id: str) -> dict | None:
data = redis.get(f"session:{session_id}")
if data:
return json.loads(data)
return None
2. الحد من المعدل
import time
def check_rate_limit(user_id: str, max_requests: int = 100,
window_seconds: int = 60) -> bool:
key = f"ratelimit:{user_id}:{int(time.time()) // window_seconds}"
count = redis.incr(key)
if count == 1:
redis.expire(key, window_seconds)
return count <= max_requests
# Token bucket algorithm (more precise)
def token_bucket(user_id: str, capacity: int = 100,
refill_rate: float = 1.0) -> bool:
key = f"token_bucket:{user_id}"
now = time.time()
lua = """
local key = KEYS[1]
local now = tonumber(ARGV[1])
local capacity = tonumber(ARGV[2])
local refill_rate = tonumber(ARGV[3])
local bucket = redis.call('HMGET', key, 'tokens', 'last_refill')
local tokens = tonumber(bucket[1]) or capacity
local last_refill = tonumber(bucket[2]) or now
local elapsed = now - last_refill
tokens = math.min(capacity, tokens + elapsed * refill_rate)
if tokens >= 1 then
tokens = tokens - 1
redis.call('HMSET', key, 'tokens', tokens, 'last_refill', now)
return 1
else
return 0
end
"""
return bool(redis.eval(lua, 1, key, now, capacity, refill_rate))
3. المتصدرين في الوقت الحقيقي
def add_score(game_id: str, player: str, score: int):
redis.zadd(f"leaderboard:{game_id}", {player: score})
def get_top_players(game_id: str, n: int = 10) -> list[dict]:
results = redis.zrevrange(
f"leaderboard:{game_id}", 0, n - 1,
withscores=True
)
return [
{"player": player.decode(), "score": int(score)}
for player, score in results
]
def get_player_rank(game_id: str, player: str) -> int:
rank = redis.zrevrank(f"leaderboard:{game_id}", player)
return rank + 1 if rank is not None else None
4. قائمة انتظار الرسائل / Pub-Sub
# PUBLISH/SUBSCRIBE
# Publisher
redis.publish("notifications:global",
json.dumps({"type": "alert", "message": "System update at 2AM"}))
# Subscriber (separate process)
pubsub = redis.pubsub()
pubsub.subscribe("notifications:global")
for message in pubsub.listen():
if message['type'] == 'message':
process_notification(json.loads(message['data']))
# List-based queue (reliable)
redis.lpush("task_queue", json.dumps(task))
task = redis.brpop("task_queue") # Blocking pop
تحسين الأداء
تأثير التسلسل
| التنسيق | التسلسل | إلغاء التسلسل | الحجم (1000 قطعة) |
|---|---|---|---|
| مخلل (بيثون) | 1x | 1x | 100 كيلو بايت |
| JSON | 0.8x | 0.7x | 180 كيلو بايت |
| حزمة الرسائل | 0.6x | 0.5x | 130 كيلو بايت |
| بروتوبوف | 0.9x | 0.4x | 75 كيلو بايت |
| ثنائي مخصص | 0.3x | 0.2x | 55 كيلو بايت |
خط الأنابيب (تقليل الرحلات ذهابًا وإيابًا)
# Without pipeline: N round-trips
for user_id in user_ids:
redis.get(f"user:{user_id}") # N network calls
# With pipeline: 1 round-trip
pipe = redis.pipeline()
for user_id in user_ids:
pipe.get(f"user:{user_id}")
results = pipe.execute() # Single network call
تجمع الاتصال
import redis
class RedisPool:
_instance = None
_pool = None
@classmethod
def get_connection(cls) -> redis.Redis:
if cls._pool is None:
cls._pool = redis.ConnectionPool(
host='redis-cluster.example.com',
port=6379,
max_connections=100,
socket_timeout=2,
retry_on_timeout=True,
health_check_interval=30,
)
return redis.Redis(connection_pool=cls._pool)
المراقبة
# Redis INFO
redis-cli INFO
# Key metrics to monitor:
connected_clients: 42
used_memory_human: 3.2G
used_memory_peak_human: 4.1G
total_commands_processed: 15238912
keyspace_hits: 984532
keyspace_misses: 5214
expired_keys: 11245
evicted_keys: 0
instantaneous_ops_per_sec: 4532
| متري | تحذير | حرجة | العمل |
|---|---|---|---|
| استخدام الذاكرة | > 80% من الحد الأقصى للذاكرة | > 95% | قم بتوسيع نطاق وتحسين TTL |
| معدل الضرب | < 85% | < 70% | مراجعة استراتيجية التخزين المؤقت |
| تأخر النسخ المتماثل | > 1 ثانية | > 10 ثواني | التحقق من الشبكة، النسخة المتماثلة |
| مفاتيح طردت | > 0 | > 100/ساعة | زيادة الذاكرة أو TTL |
الاستنتاج
تعد قواعد البيانات الموجودة في الذاكرة بنية أساسية أساسية للتطبيقات الحديثة عالية الأداء:
- استخدام للتخزين المؤقت — تقليل تحميل قاعدة البيانات وتحسين أوقات الاستجابة.
- الاستخدام للبيانات في الوقت الفعلي — لوحات المتصدرين، وتحديد المعدل، وإدارة الجلسة.
- الاستخدام كوسيط رسائل — Pub/sub، وقوائم انتظار المهام، وتدفقات الأحداث.
- Redis هو الخيار الافتراضي — هياكل البيانات الغنية، وخيارات الثبات، والتجميع.
- لا تستخدم مطلقًا كقاعدة بيانات أساسية — خطر فقدان البيانات، وقيود الذاكرة، وقدرة الاستعلام المحدودة.
إطار القرار
Need sub-millisecond latency?
├─ Yes
│ Q: Complexity of operations?
│ ├─ Simple key-value: Memcached
│ ├─ Data structures, persistence: Redis
│ └─ Distributed computing: Hazelcast/Ignite
└─ No
Q: Data fits in memory?
├─ Yes: Consider in-memory for performance
└─ No: Disk-based (PostgreSQL, etc.)
لا تهدف قواعد البيانات الموجودة في الذاكرة إلى استبدال قواعد البيانات، بل تهدف إلى جعل كل شيء أسرع.
التعليقات
0 تعليقاتلا توجد تعليقات معتمدة بعد. قد تنتظر الردود الجديدة المراجعة.